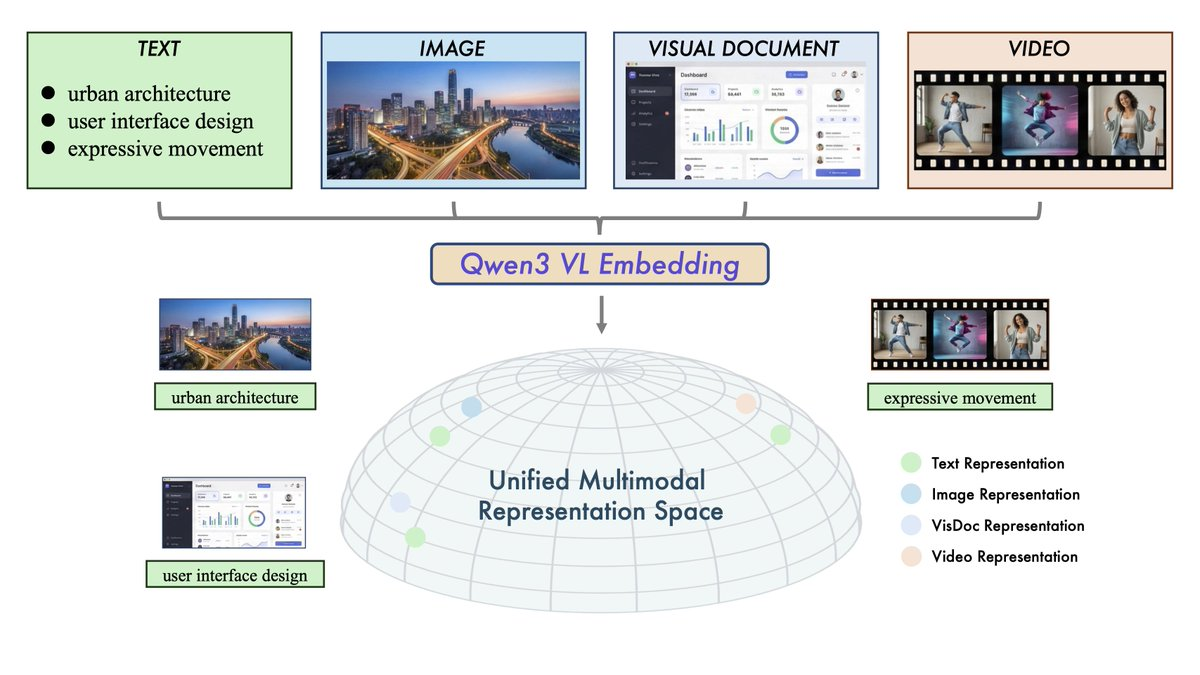
一、摘要
Qwen3-VL-Embedding 与 Qwen3-VL-Reranker 是基于 Qwen3-VL 的开源多模态检索模型系列,面向“文本+图像+截图+视频+混合输入”的跨模态理解与检索。整体采用两阶段架构:先用 Embedding 做大规模向量召回,再用 Reranker 做细粒度相关性打分,以提升最终检索准确率,并覆盖 30+ 语言场景。
二、核心特性
1、多模态输入统一化:同一套框架处理文本、图片、截图、视频及混合模态。
2、两阶段检索范式:Embedding 负责高效召回;Reranker 负责精排对齐与纠错。
3、可配置向量维度:Embedding 支持灵活输出维度(典型用于在效果与成本间权衡)。
4、指令可定制:可通过任务指令(instruction)适配“检索/聚类/VQA/多模态 RAG”等不同目标。
5、量化与工程友好:支持对 embedding 输出进行量化以降低存储与检索成本;上下文长度面向长输入场景设计。
三、安装
1、克隆仓库并按脚本创建环境(仓库提供一键环境脚本,适合复现示例)。
2、下载权重:可从 Hugging Face 或 ModelScope 拉取对应大小(2B/8B)的 Embedding 与 Reranker。
3、准备运行依赖:常见依赖包括 Transformers、PyTorch 以及与多模态预处理相关的工具包;版本以仓库/模型卡为准。
四、典型用例
1、图文检索:用文本找图、用图找文本(电商、媒体素材库、知识库)。
2、视频搜索/视频-文本匹配:用自然语言检索视频片段或候选视频。
3、多模态 RAG:把图文页、截图、图表等内容向量化召回,再用 Reranker 精排提高答案依据质量。
4、视觉问答与内容聚类:用统一向量空间做相似内容聚合、去重与主题分群。
5、多语言视觉搜索:跨语言查询与跨模态内容对齐(国际化站点、跨境业务)。
五、生态与竞品
1、生态:模型在 GitHub、Hugging Face、ModelScope 提供下载与示例,便于接入现有向量库/检索框架;官方也提到后续将提供云端 API 部署能力。
2、竞品:多模态向量检索常见路线包括 CLIP/SigLIP/OpenCLIP 等“图文对比学习”向量模型,以及各类多模态/跨编码器(cross-encoder)精排模型。Qwen3-VL-Embedding + Reranker 的差异点在于:同源多模态底座、两阶段协同、指令化与可配维度带来的工程弹性。
六、局限与注意事项
1、两阶段链路更复杂:需要维护向量库与精排服务,系统设计与监控成本更高。
2、视频与长上下文成本:视频解码/抽帧与长序列推理会显著增加算力与延迟。
3、指令与数据敏感:不同业务语料、语言与模态分布会影响效果,建议做小规模标注评测与提示词迭代。
4、量化需验证:量化可能带来精度波动,应在关键指标上做回归测试。
七、项目地址
https://github.com/QwenLM/Qwen3-VL-Embedding
八、常见问题
Q: Qwen3-VL-Embedding 如何用于多模态检索召回?
A: 先将“图/文/视频内容(或其表示)”编码成向量入库;查询侧同样编码成向量做相似度检索,得到候选集合。
Q: Qwen3-VL-Reranker 在检索流程里解决什么问题?
A: 它对候选进行细粒度相关性打分,缓解“向量召回误匹配、跨模态弱对齐”等问题,提升 Top-K 精度。
Q: 可配置 embedding 维度对成本有什么影响?
A: 维度越小,存储与向量检索速度通常更友好;但可能损失部分表达能力,需要在业务指标上做权衡。
Q: 多语言检索时指令(instruction)应该怎么写?
A: 通常建议为任务定制清晰指令;若跨语言场景复杂,可优先用英文指令并在目标语料上评测效果。
Q: 多模态 RAG 是否必须先 OCR 截图/图片?
A: 不一定;若模型与流程支持直接处理图像/截图,可直接走多模态编码与精排。但在“可检索片段化、可解释引用”等要求更强时,OCR/版面解析仍可能提升可控性。