Xiaomi MiMoとXiaomi大型モデルCoreチームはMiMo-V2-Flash関連リソースを公開・公開し、高速推論やエージェントワークフローの基本言語モデルとして位置づけ、モデルの重みと推論展開データを開発者と研究者に同時に提供しています。
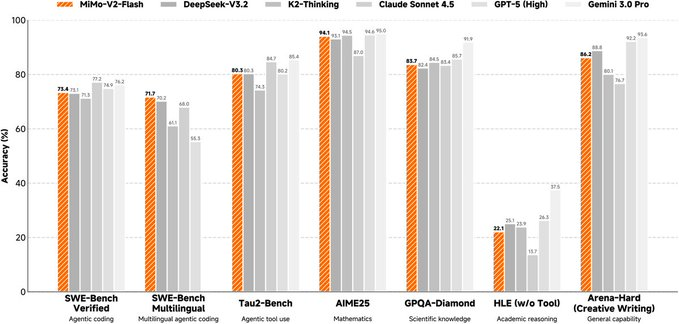
このモデルはMixture-of-Experts(MoE)アーキテクチャで、総パラメータは約309B、推論中の活性化は約15B、最大コンテキスト長は約256Kをサポートしています。 混合注意設計はスライドウィンドウの注意とグローバル注意を比例的に絡み合わせ、より小さなウィンドウでKVキャッシュのオーバーヘッドを圧縮しています。 同時に、復号出力速度を向上させる軽量マルチトークン予測(MTP)モジュールが導入され、公式サイトはコミュニティ研究用の追加の多層MTP重みも提供しています。 モデルページとリポジトリでは、トレーニングおよびトレーニング後のポイント(FP8の混合精度およびエージェント指向の強化学習・蒸留ルートを含む)を提供し、複数の評価結果を比較のために一覧化しています。
このような超大規模MoEモデルは計算能力や推論フレームワークに高い要求を抱え、評価結果や実際のビジネス効果はプロンプト、ツールチェーン、並列定量化および推論戦略によって影響を受ける可能性があることに注意が必要です。 商用利用や再配布の前に、モデルページやコードリポジトリの具体的なライセンス条件や範囲も確認してください。
FAQ
Q: MiMo-V2-Flashはどのタイプのモデルですか?
A: MiMo-V2-Flashは、XiaomiのMiMoチームがリリースしたMoEの基本言語モデルで、高速推論およびエージェントタスクシナリオを目的としています。
Q: MiMo-V2-Flashのパラメータサイズとコンテキストの長さはどれくらいですか?
A: 公開情報によると、その総パラメータは約309B、活性化は約15B、最大コンテキスト長は約256Kです。
Q: MiMo-V2-Flashは「混合注目」とMTPで主にどのような問題を解決しますか?
A: Mixed Attentionは長いコンテキスト推論におけるKVキャッシュコストの削減に焦点を当てており、MTPはデコード段階での出力スループットと速度の向上に注力しています。
Q: MiMo-V2-Flashのモデルの重量や技術レポートはどこで入手できますか?
A: モデルの重みはHugging Faceで入手可能で、コードや技術レポートはGitHubリポジトリで入手可能で、公式ウェブサイトのブログやLMSYSの記事も整理されています。
Q: MiMo-V2-Flashが展開時に最もよく踏みつける穴は何ですか?
A: よくある問題には、メモリや帯域幅の不足、MoEやMTPの推論フレームワークのサポートが不完全、量子化や並列構成の不適切なため速度や品質の変動が挙げられます。