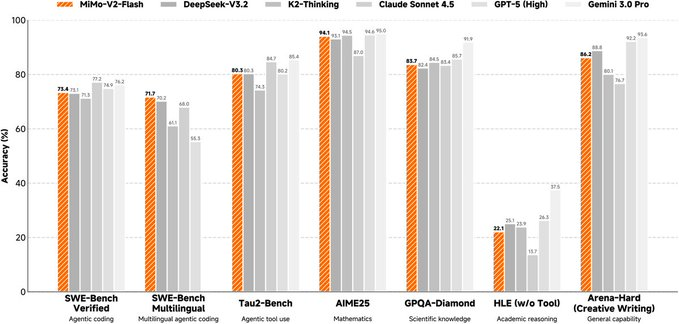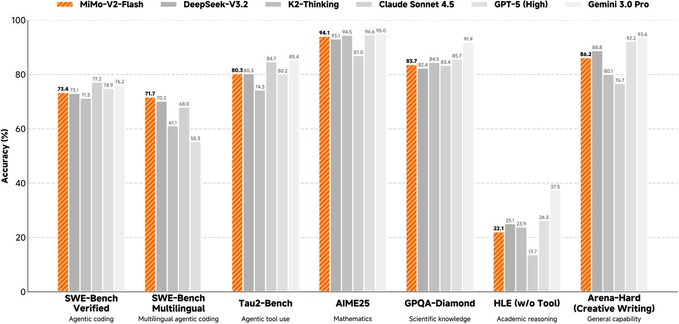
Xiaomi MiMo and the Xiaomi large model Core team have released and opened MiMo-V2-Flash-related resources, positioning it as a basic language model for high-speed reasoning and agent workflows, and the model weight and inference deployment data are provided to developers and researchers simultaneously.
The model is a Mixture-of-Experts (MoE) architecture with a total parameter of about 309B, activation of about 15B during inference, and supports a maximum context length of about 256K. Its mixed attention design intertwines sliding window attention with global attention in proportion, and uses a smaller window to compress KV cache overhead. At the same time, a lightweight multi-token prediction (MTP) module is introduced to improve the decoding output speed, and the official also provides additional multi-layer MTP weights for community research. The model page and repository provide training and post-training points (including FP8 mixed precision and agent-oriented reinforcement learning/distillation routes), and list multiple evaluation results for comparison.
It should be noted that such ultra-large-scale MoE models have high requirements for computing power and inference frameworks, and the evaluation results and actual business effects may be affected by prompts, tool chains, and parallel quantification and inference strategies. Before commercial use and redistribution, you should also check the specific license terms and scope of the model page and code repository.
FAQ
Q: What type of model is MiMo-V2-Flash?
A: MiMo-V2-Flash is a MoE basic language model released by the Xiaomi MiMo team, which is aimed at high-speed inference and agent task scenarios.
Q: What is the parameter size and context length of MiMo-V2-Flash?
A: Public information shows that its total parameters are about 309B, activation is about 15B, and it supports a maximum context length of about 256K.
Q: What problems does the MiMo-V2-Flash mainly solve with "mixed attention" and MTP?
A: Mixed attention focuses on reducing the KV caching cost of long context inference, while MTP focuses on improving output throughput and speed in the decoding stage.
Q: Where can I get the model weights and technical reports for MiMo-V2-Flash?
A: Model weights are available on Hugging Face, code and technical reports are available in the GitHub repository, and the official website blog and LMSYS articles are also organized.
Q: What is the most common pit for MiMo-V2-Flash to step on when deploying?
A: Common issues include insufficient memory/bandwidth, incomplete inference framework support for MoE and MTP, and improper quantization and parallel configuration leading to speed or quality fluctuations.