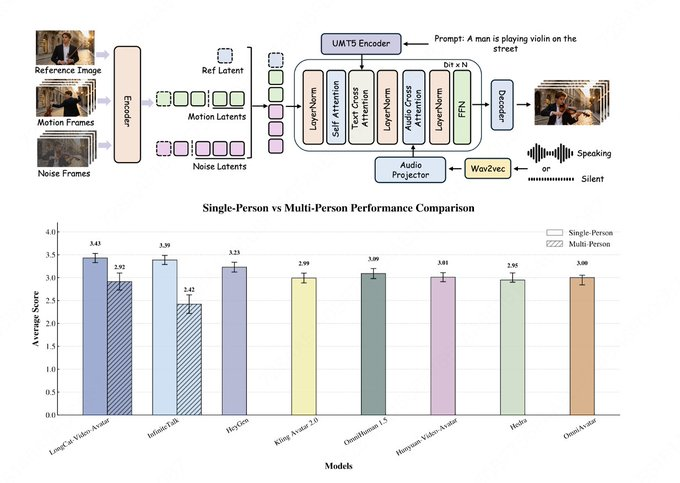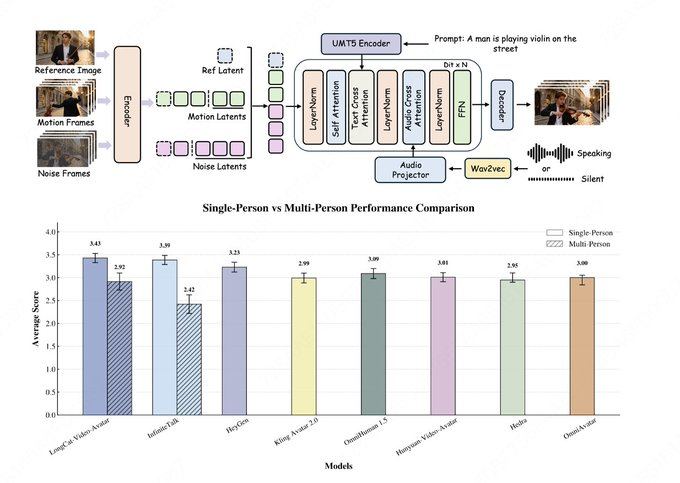
美団のLongCatチームは、LongCat-VideoコードベースのアップデートでLongCat-Video-Avatarのリリースを発表し、同時にプロジェクトページとHugging Faceの重りを公開しました。 LongCat-Videoアーキテクチャをベースに、このモデルはAudio-Text-to-Video(AT2V)、Audio-Text-Image-to-Video(ATI2V)、および音声条件によるビデオ継続をサポートし、単一人物、多文字、長時間のコンテンツ生成に対応しています。
公開資料によると、LongCat-Video-Avatarは長シーケンスの安定性とより自然な動的パフォーマンスに焦点を当てています。クロスチャンク・ラテントスティッチングは長尺動画生成における劣化や継ぎ目問題を減らし、リファレンススキップアテンションを用いて「ハードコピー」トレースを減らしつつアイデンティティの一貫性を維持します。 同時に、音声信号への過度依存を減らし、無音セグメントの硬さの問題を改善するためにデカップリング誘導戦略も提案されています。 チームはモデルカードの人間評価のベンチマークとしてEvalTalkerを引用し、自然さとリアリズムの比較を示しましたが、外部リストランキングや参加者数などの詳細は公開ページで完全には公開されておらず、関連する結論は評価論文と再現可能な実験に基づいています。
よくある質問:
LongCat-Video-Avatarはどのモデルですか?
A: LongCat-Video-Avatarは、長時間のタイミング安定性、リップシンク、アイデンティティの一貫性を重視したキャラクターパフォーマンスのための音声駆動型ビデオ生成モデルです。
Q: 美環のLongCatチームがリリースしたLongCat-Video-Avatarは、どのような世代モードをサポートしていますか?
A: LongCat-Video-AvatarはAT2V、ATI2V、さらに音声条件のためのビデオ継続や長映像展開をサポートしています。
Q: LongCat-Video-AvatarとInfiniteTalkの違いは何ですか?
A: LongCat-Video-Avatarは導入部でより自然なダイナミクスと安定した長シーケンス性能を強調し、参照画像注入による「コピー&ペースト」アーティファクトを減らすためにReference Skip Attentionを用いています。
Q: LongCat-Video-Avatarを使用する際に開発者が注意すべきリスクは何ですか?
A: 開発者はポートレートや音声のライセンス、コンプライアンス、コンテンツセキュリティに注意を払い、許可なく誤用されたキャラクターコンテンツを生成しないよう注意する必要があります。