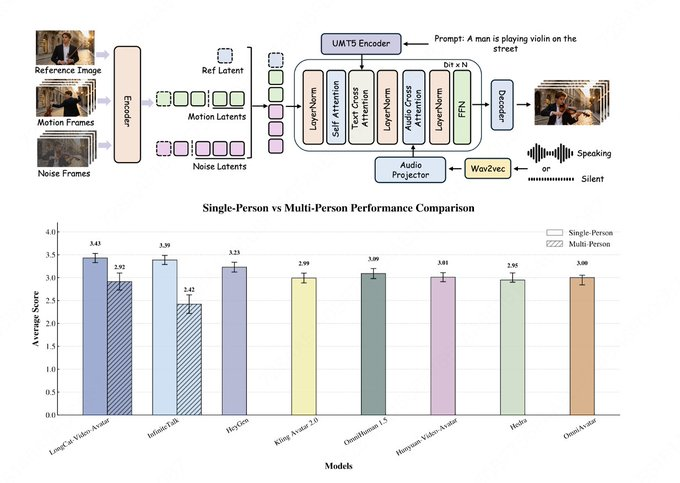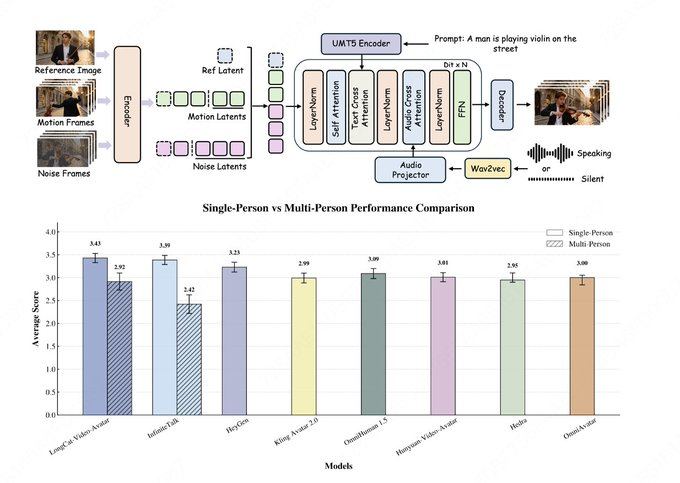
L’équipe LongCat de Meituan a annoncé la sortie de LongCat-Video-Avatar dans la mise à jour de la base de code LongCat-Video, tout en lançant simultanément la page projet et les poids Hugging Face. Basé sur l’architecture LongCat-Video, le modèle prend en charge l’audio-texte-vers-vidéo (AT2V), audio-texte-image-verse-vidéo (ATI2V) et la continuation vidéo avec conditions audio, couvrant la génération de contenu individuelle, multi-caractères et de longue durée.
Selon les documents publics, LongCat-Video-Avatar met l’accent sur la stabilité des longues séquences et une performance dynamique plus naturelle : le point latent en croix réduit la dégradation et les problèmes de couture lors de la génération vidéo longue, et utilise l’attention de saut de référence pour réduire les traces « papier » tout en maintenant la cohérence de l’identité ; Parallèlement, une stratégie de guidage de découplage est proposée pour réduire la dépendance excessive aux signaux vocaux et améliorer le problème des segments silencieux trop rigides. L’équipe a cité EvalTalker comme référence pour l’évaluation humaine dans la fiche modèle et a montré la comparaison entre naturel et réalisme, mais des détails tels que les classements externes des listes et la taille des participants n’ont pas été entièrement divulgués sur la page publique, et les conclusions pertinentes doivent encore être basées sur l’article d’évaluation et les expériences reproductibles.
FAQ
Q : Quel modèle est le LongCat-Video-Avatar ?
R : LongCat-Video-Avatar est un modèle de génération vidéo audio pour la performance des personnages, mettant l’accent sur la stabilité de longévité, la synchronisation labiale et la cohérence des identités.
Q : Quels modes génération le LongCat-Video-Avatar sorti par l’équipe LongCat de Meituan prend-il en charge ?
R : LongCat-Video-Avatar prend en charge AT2V, ATI2V, ainsi que la continuation vidéo et l’extension vidéo longue pour les conditions audio.
Q : Quelle est la différence entre LongCat-Video-Avatar et InfiniteTalk ?
R : LongCat-Video-Avatar met l’accent sur une dynamique plus naturelle et une performance plus stable en longues séquences dans l’introduction, et utilise Reference Skip Attention pour réduire l’artefact de « copier-coller » causé par l’injection d’images de référence.
Q : Quels risques les développeurs doivent-ils connaître lorsqu’ils utilisent LongCat-Video-Avatar ?
R : Les développeurs doivent prêter attention aux licences portrait et audio, à la conformité et à la sécurité du contenu, et éviter de générer du contenu de personnages mal utilisé sans autorisation.