I. Abstract
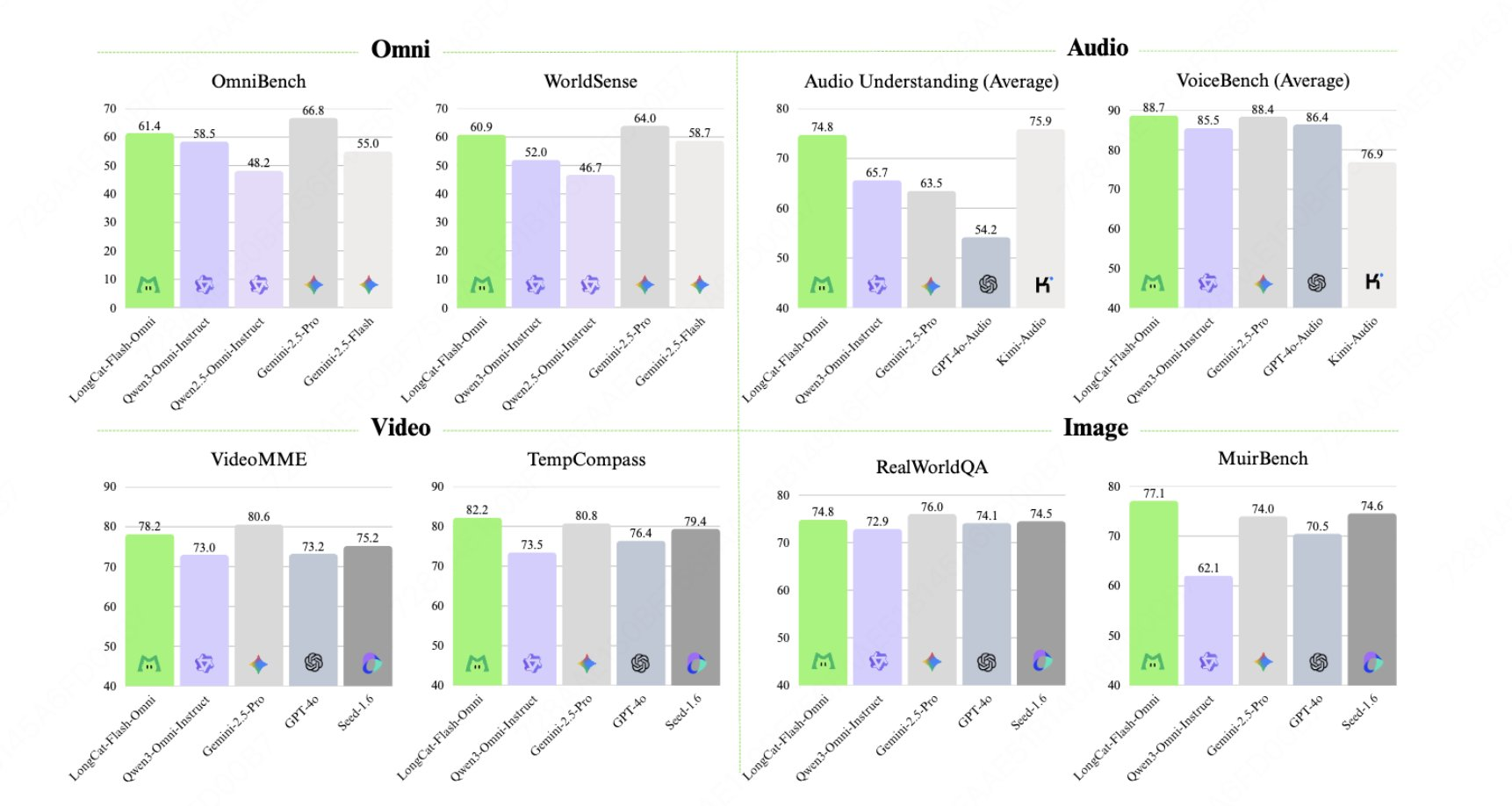
LongCat-Flash-Omni is an open-source, multimodal (Omni-modal) model from Meituan's LongCat team. It extends the ScMoE architecture of LongCat-Flash by providing unified modeling for text, images, audio, and video. It has approximately 560 bytes of parameters and 27 bytes of activations, primarily targeting millisecond-level end-to-end voice dialogue, 128K context, and real-time audio and video interaction scenarios exceeding 8 minutes. Its key features include early multimodal fusion training, decoupled modal parallel infrastructure, and the accompanying LongCat-Audio-Codec for high-quality speech output.
II. Core Features
- Full-modal I/O: Input can be any combination of text, image, audio, or video, and output text or voice, adapting to real-time agents.
- Low-latency speech: End-to-end speech understanding and synthesis latency is controlled at the millisecond level, which is suitable for "interrupted" dialogue.
- Long context: Native 128K, which can support long meetings, multi-turn voice and long video understanding.
- ScMoE architecture: 560B total parameters + 27B activations, with computational cost approaching the efficiency of pure text training.
- Unified training paradigm: Integrate multimodal training in the early stages to avoid losing points in a single modality, and take into account listening, watching and speaking.
III. Installation
1. Clone the GitHub repository: git clone https://github.com/meituan-longcat/LongCat-Flash-Omni and enter the directory.
- Install dependencies according to the environment instructions provided in the repository. You can choose between vLLM/SGLang/self-developed inference service. A GPU is required and it is recommended that the video memory be ≥40GB. Multiple GPUs can be used in parallel.
3. Pull the corresponding weights and examples from Hugging Face: https://huggingface.co/meituan-longcat/LongCat-Flash-Omni; If voice output is required, install LongCat-Audio-Codec simultaneously.
- After deployment, conduct text/voice tests via REST/WebSocket or the official LongCat.AI frontend.
IV. Typical Use Cases
- Real-time voice assistant: outbound calls, customer service, and companionship interactions, requiring low latency and multi-turn memory.
- AV Scene Understanding: Extract key points and answer questions from audio and video inputs for meetings/live broadcasts/courses.
- Text and audio explanation: Input screenshots/photos/documents to generate audio explanations or multilingual summaries.
- Agent Project Entry Point: Hands over the video/voice perception results to the toolchain or business process for further execution.
V. Ecology and Competitors
- Ecosystem: Complementary to LongCat-Flash-Chat, LongCat-Flash-Thinking, and LongCat-Audio-Codec, enabling unified versions and training paradigms within the same organization.
- Competitors: The capabilities of Qwen series Omni, InternLM/GLM speech multimodal versions, and MiniCPM-O/Omni-like models from various communities are comparable; LongCat's long context + millisecond-level speech is the differentiating factor.
- Application side: The official website provides iOS/Android App and Web experience site to facilitate verification of voice link performance.
VI. Limitations and Precautions
- True low latency relies on end-to-end voice links and high-bandwidth inference services, which cannot be fully reproduced on local or low-spec machines.
- Video/long audio input will significantly increase video memory and computing power, so it is necessary to trim or segment according to the scenario.
- While early multimodal fusion can improve consistency, it is sensitive to data format and annotation quality. Secondary training must strictly align with the official examples.
- Open source repositories are updated frequently, and deployment scripts, quantization methods, and model sharding should be based on the latest versions.
VII. Project Address
https://github.com/meituan-longcat/LongCat-Flash-Omni
VIII. Frequently Asked Questions
Q: Does LongCat-Flash-Omni require an internet connection to perform inference?
A: The weights are open source and can be deployed locally or privately, but for speech synthesis and large-scale multimodal inference, it is recommended to use a GPU cluster to achieve the real-time performance shown in the official documentation.
Q: In what scenarios is the 128K context primarily used?
A: Suitable for long meetings, segmented understanding of long videos, and maintaining the state of multi-turn voice dialogues. It can also be used as a long document input window for multimodal RAGs.
Q: If only voice input and output are needed, is it necessary to load the full 560B?
A: The official architecture is ScMoE, with an actual activation of approximately 27 bytes. It can be combined with quantization/pruning and single-task fine-tuning to reduce resource consumption; please refer to the repository deployment instructions for details.


