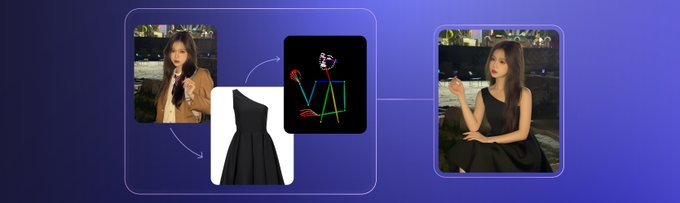
Qwenチームは、Qwen-Image-Editの月例リデザインであるQwen-Image-Edit-2509をリリースしました。これは、複数画像編集と単一画像における一貫性に重点を置いたものです。複数画像モードでは、「人物 + 製品」や「人物 + 風景」など、最大1~3枚の参照画像をドラッグしてモデル合成時に被写体と材質の一貫性を維持できるため、位置ずれや「つなぎ合わせた」ような感覚を最小限に抑えることができます。単一画像編集では、顔はポーズやスタイルを問わずに、製品は広告やポスターの主要な特徴を維持します。テキスト編集では、コンテンツ、フォント、色、テクスチャを同時に変更できるため、長いテキストのレイアウトやテキストと画像の統合が可能です。
このバージョンは、ControlNetの条件付き入力(深度、エッジ、キーポイントなど)をネイティブにサポートしており、ポーズの置換と構造のアライメントを容易にします。QwenChat画像編集ポータル、Hugging Faceモデルとデモ、GitHubのチュートリアル、ModelScope画像など、公式オンラインエクスペリエンスとオープンソースリソースをご利用いただけます。GGUF量子化とComfyUIの適応に関するコミュニティの議論も開始されています。具体的な機能とベストプラクティスについては、公式ドキュメントとリポジトリをご覧ください。
よくある質問
Q: 以前のバージョンと比べて、主な改善点は何ですか?
A: 複数画像編集機能が追加され、単一画像内の文字と製品の一貫性が大幅に向上しました。テキスト編集では、フォント/色/素材などの細かい制御がサポートされます。
Q: 複数画像編集に推奨される入力量はどれくらいですか?
A: 現在は1~3枚の写真が最適で、「人物+人物/人物+商品/人物+シナリオ」などの組み合わせがサポートされています。
Q: ControlNet は組み込まれていますか?
A: はい、姿勢や構造の制御のための深度、エッジ、キーポイントなどの条件付き入力をネイティブにサポートしています。
Q: モデルを体験したり入手したりするにはどこでできますか?
A: QwenChat の画像編集ポータルを使用できます。GitHub/Hugging Face/ModelScope では、重み、例、オンライン デモが提供されています。
Q: これはオープンソースですか?
A: モデルの重みとサンプルコードが提供されています。コミュニティはすでに定量化とワークフローの適応を実装しています。具体的な権限と使用方法については、プラットフォームのページをご覧ください。