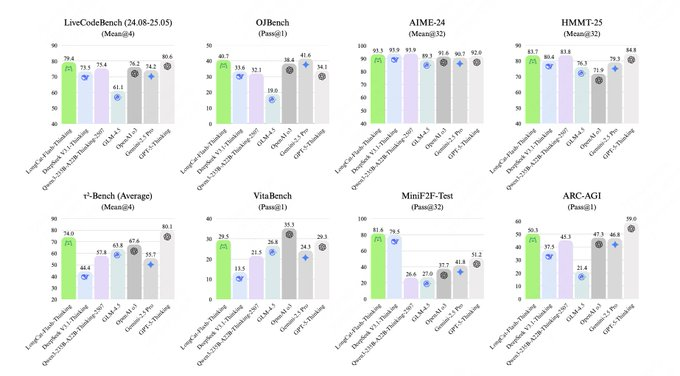
LongCat-Flash-Thinking combine l'IA avec le MoE, l'apprentissage par renforcement asynchrone et les outils natifs des agents, atteignant des performances de pointe dans les tâches de logique, de mathématiques, de codage et d'agent. AIME25 atteint une grande précision avec moins de jetons, ce qui le rend idéal pour les entreprises qui souhaitent obtenir une inférence de haute qualité et une implémentation stable à faible coût. I. Pourquoi il vaut la peine de le déployer maintenant 1. Points forts de l'architecture : Activation dynamique du MoE (LongCat-Flash-Thinking) L'IA active les experts à la demande via le MoE, préservant l'inférence profonde tout en réduisant la surcharge d'inférence et l'utilisation de la mémoire, prenant en charge la décomposition des problèmes à longue chaîne et les résultats interprétables. 2. Efficacité et coût : AIME25 économise des jetons (LongCat-Flash-Thinking) L'IA s'appuie sur des outils natifs et des stratégies conviviales pour les agents pour réduire considérablement le nombre de jetons nécessaires pour atteindre une précision de haut niveau, optimisant ainsi le coût et la latence de l'inférence, et facilitant les services en ligne à grande échelle. 3. Infrastructure : Triple accélération du RL asynchrone (LongCat-Flash-Thinking). Le RL asynchrone dissocie l'échantillonnage et l'optimisation pour améliorer le débit et la stabilité. Il combine la lecture des données et l'évaluation automatique pour raccourcir les cycles d'itération et former une boucle fermée rapide de la formation au déploiement.
II. Méthodes de mise en œuvre et liste des scénarios
1. Chemin de déploiement (LongCat-Flash-Thinking)
(1) Cadre de raisonnement : prioriser vLLM ou SGLang, combiné à KV Cache et au traitement par lots
(2) Stratégie de ressources : les tâches simples nécessitent une réflexion approfondie, les tâches complexes nécessitent une réflexion et des outils
(3) Indicateurs d'observation : enregistrer les jetons, les retards, les taux de réussite et automatiser l'ajustement des paramètres
2. Mots d'invite et pipeline d'agent (LongCat-Flash-Thinking)
(1) Déterminer si un outil est nécessaire avant de saisir l'appel de fonction
(2) Définir des modèles d'entrée et de sortie fixes pour les mathématiques et le code
(3) Configurer le délai d'expiration, la nouvelle tentative et les chemins de secours pour plusieurs outils simultanément
(3) Applications typiques (LongCat-Flash-Thinking)
a. Réparation du code et localisation de la régression
b. Agent basé sur les processus avec recherche et calcul
c. Génération de rapports et automatisation des questions-réponses complexes
III. Points clés pour la mesure des performances et la gouvernance
1. Performance (IA + LongCat-Flash-Thinking)
Évaluer en fonction de la précision, de l'explicabilité des étapes et du taux de réussite de l'agent, en mettant l'accent sur la stabilité du lien à long terme et la rejouabilité.
2. Coût (IA + LongCat-Flash-Thinking)
Surveillez les jetons par tâche, les pics de mémoire et la latence de bout en bout pour quantifier les avantages A/B et permettre une optimisation continue.
3. Gouvernance (IA + LongCat-Flash-Thinking)
Consolidez les modèles d'invite unifiés, les versions de données et les journaux pour réduire la sensibilité des invites et le risque de dérive.
Foire aux questions (Q&R)
Q : Quelles sont les performances de LongCat-Flash-Thinking dans les tâches d’IA ?
R : Il se classe parmi les leaders SOTA open source en logique, mathématiques, programmation et tâches d’agent, mettant l’accent sur un raisonnement stable et une évaluation reproductible.
Q : Pourquoi est-il plus efficace dans AIME25 ?
R : Nous utilisons des outils natifs et des stratégies conviviales pour les agents afin de prioriser les décisions avant de les invoquer, réduisant ainsi la réflexion inefficace à long terme et diminuant les coûts d’inférence tout en maintenant la même précision.
Q : Quels sont les avantages directs du RL asynchrone pour l’ingénierie ?
R : Un débit d’apprentissage amélioré, une convergence plus stable et une itération plus rapide nous aident à mettre rapidement en ligne les améliorations des modèles et à vérifier leurs avantages.
Q : Comment les entreprises peuvent-elles démarrer rapidement et contrôler les coûts ?
R : Choisissez un moteur d’inférence à haut débit, activer le traitement par lots et la mise en cache ; utiliser un commutateur de réflexion pour différencier la difficulté des tâches ; surveiller en permanence les jetons et la latence et ajuster automatiquement les paramètres.