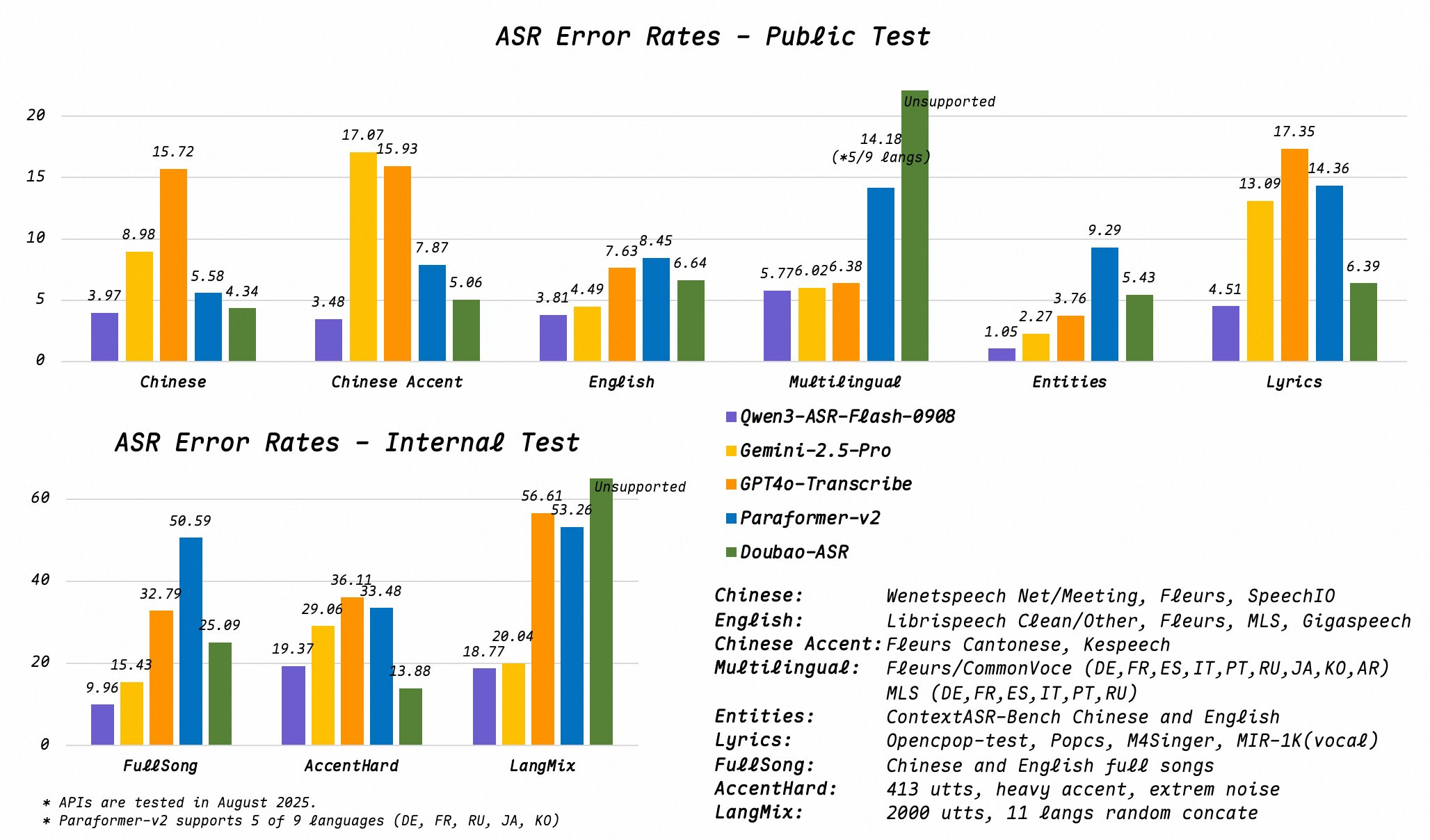
Qwen3-ASRは、アリババ通義Qianwenが立ち上げた統合AI音声認識モデルで、中国語、英語、9つの共通言語をサポートし、自動言語検出機能を備え、歌、ラップ、BGM、ノイズ、遠距離シーンでタイプミス率を8%未満に維持し、カスタムコンテキスト語彙をサポートしているため、固有名詞の認識効果が大幅に向上し、教育、メディア、カスタマーサービス、その他の業界に適しています。
1. Qwen3-ASR の主な利点
1. 多言語および自動検出
Qwen3-ASR は、中国語、英語、アラビア語、ドイツ語、スペイン語、フランス語、イタリア語、日本語、韓国語、ポルトガル語、ロシア語を含む合計 11 の言語をサポートしており、AI が言語を自動的に認識します。 モデルを手動で切り替える必要がないため、言語間シナリオの効率が大幅に向上します。
2. 複雑な音響環境での堅牢なパフォーマンス
Qwen3-ASR は、曲、ラップ、BGM、騒がしい遠距離音声でも、タイプミス率を 8% 未満に維持できます。 これにより、ライブ字幕生成、多言語インタビューの文字起こし、UGC の短編ビデオ シナリオに最適です。
3. カスタムコンテキスト機能
ユーザーは、固有名詞、人名、地名、または業界用語をコンテキスト プロンプトとして直接貼り付けることができ、Qwen3-ASR はこれらの単語に優先順位を付けて認識精度を向上させます。 この機能は、教育コンテンツ、企業カスタマーサービス、製品SKUの識別、その他のニーズに特に適しています。
2. 業界応用価値
1. 教育シナリオ
オンライン教育および録音教室では、Qwen3-ASR はトランスクリプトを自動的に生成し、科目固有の語彙リストと組み合わせて、より正確なメモと重要なポイントの要約を出力できるため、手動校正が大幅に削減されます。
2. メディアシナリオ
騒がしい環境での多言語インタビューや UGC ビデオの場合、Qwen3-ASR は安定した認識精度を維持し、それをリバース テキスト標準化された出力字幕と組み合わせて、ポストエディットの作業負荷を軽減できます。
3. 顧客サービスと品質検査
企業は、コールセンターの音声をバッチで文字起こしし、カスタマイズされたコンテキストを通じて製品名とプロセス語彙認識の精度を向上させ、ナレッジベースと組み合わせて「文字起こし-品質検査-FAQ連携」の閉ループを実現できます。
3. アクセス方法と評価ポイント
1. アクセスパス
企業は、公式 API を介して本番環境にすばやくアクセスすることも、最初にオンライン デモで音声認識効果をテストしてから、大規模なアプリケーションに移行することもできます。
2. 評価のポイント
a. 複数の言語の WER ベースラインを確立する
b. ノイズ、遠方界、BGM などのさまざまな条件下での安定性をテスト
するc. 業界用語を使用してコンテキスト関数の効果を検証
するd. 遅延、コスト、精度を組み合わせて、適切な展開スキームを選択する
よくある質問(Q&A)
Q: Qwen3-ASRのAI音声認識はどの言語をサポートしていますか?
A: 中国語、英語、アラビア語、ドイツ語、スペイン語、フランス語、イタリア語、日本語、韓国語、ポルトガル語、ロシア語を含む 11 の言語をサポートしており、言語を自動的に認識できます。
Q: 曲や騒がしい環境での AI 音声認識の精度はどのくらいですか?
A: Qwen3-ASR は、曲、ラップ、BGM、遠距離環境でもタイプミス率を 8% 未満に維持できるため、複数のシナリオでの使いやすさが保証されます。
Q: カスタムコンテキストを使用して AI 音声認識を強化するにはどうすればよいですか?
A: ユーザーは個人名、用語、SKU、または特別な単語をコンテキスト領域に貼り付けることができ、モデルがこれらの単語を最初に認識するため、誤認率が大幅に減少します。
Q: Qwen3-ASRはWhisperなどのASRツールとどう違うのですか?
A: Whisper はオープンソースのローカル展開を好みますが、Qwen3-ASR は公式 API とオンライン デモを提供しており、企業が大規模なアプリケーションを迅速に実装して実行するのに適しています。



