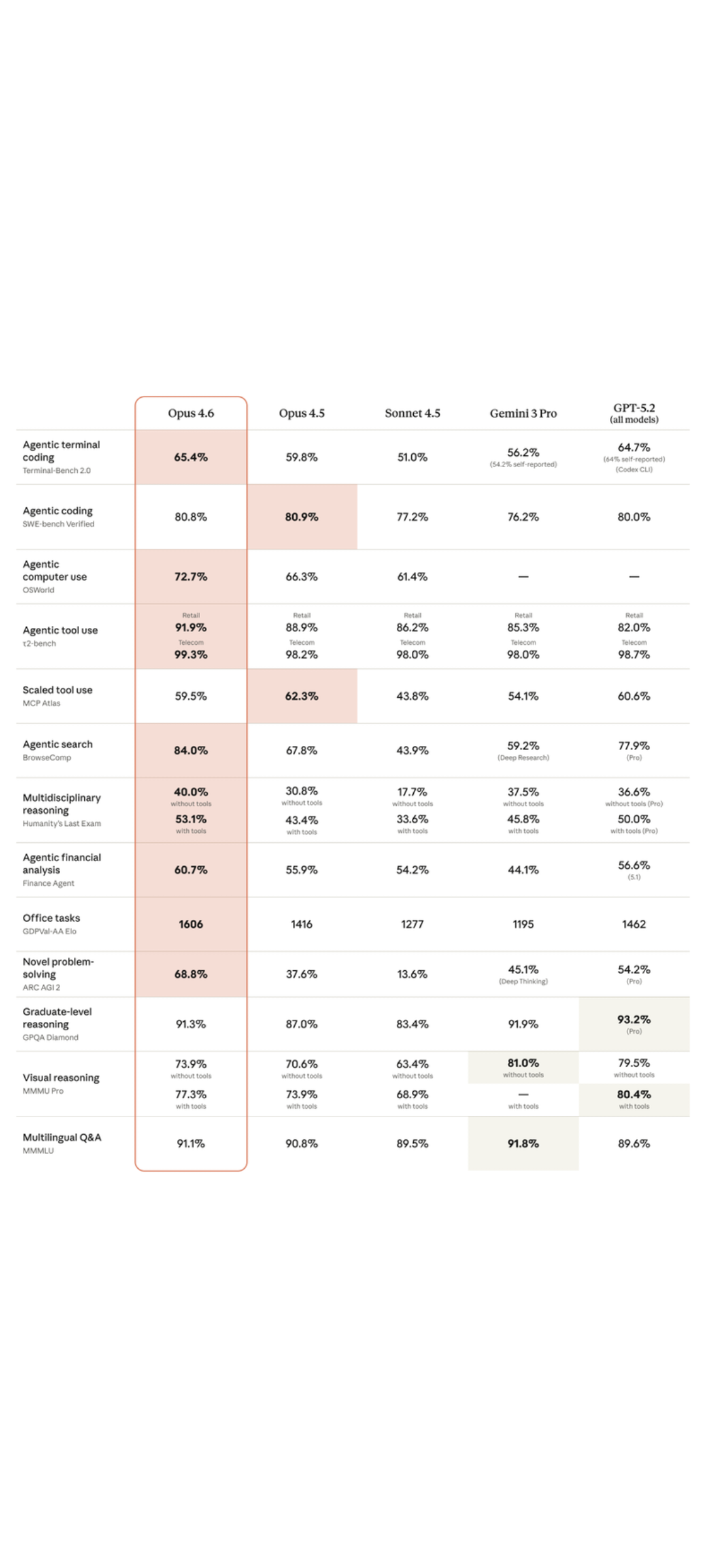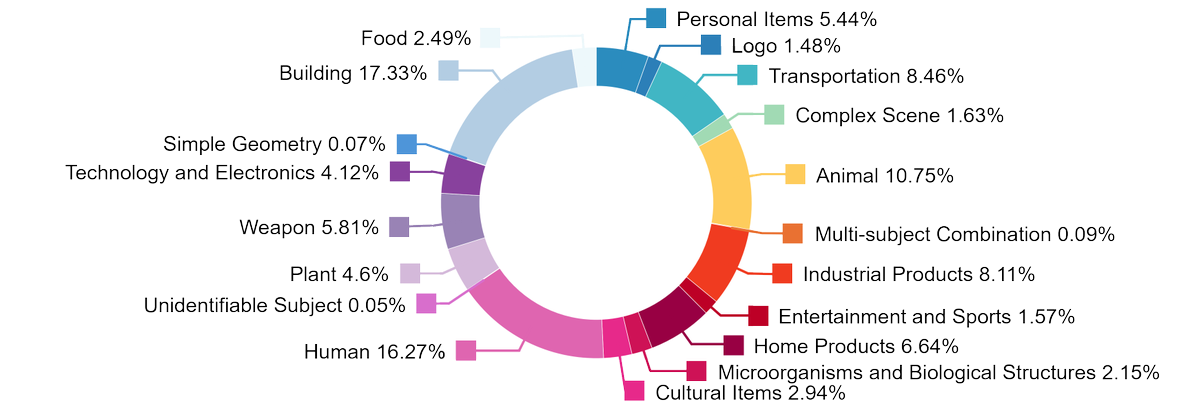
1. 要旨
HY3D-Benchは、騰訊のHunyuanチームによるオープンソースの統一3D資産データエコシステムであり、3D生成分野における「データ希少性、高いノイズ、評価の一貫性の欠如」という共通の課題を緩和することを目的としています。 プロジェクトは、フルレベル(252K+完全オブジェクト)、パートレベル(240K+コンポーネントレベルの構造分解)、合成的(125K+ AIGC合成ロングテールカテゴリ)の3種類の補完的なデータサブセットを同時に公開し、軽量で再現性の高いベースラインモデルであるHunyuan3D-Shape-v2-1 Small(0.8B)を提供しています。
2. コア機能
- トレーニング準備品質:メッシュは清掃され、正規化され、防水・マニホールド処理が施され、非マニホールドノイズや穴割れなどのトレーニングノイズを軽減します。
- 統一されたフォーマットとメタデータ:異なるサブセットはファイルの構成やフィールドがより一貫しており、データパイプラインや評価プロセスの構築が容易になります。
- フルレベル完全オブジェクト:防水メッシュ、マルチビューレンダリング、サンプリングポイントを含み、シングルビューから3Dへの再構築および生成トレーニングに適しています。
- 部品レベルのコンポーネントレベルの分解:コンポーネントラベル、コンポーネント非依存メッシュ、コンポーネントアセンブリレンダリングを提供し、細かな制御可能な生成、構造編集、ロボット操作関連の研究をサポートします。
- 合成ロングテール補完:1,252の細粒度サブクラスをカバーし、ターゲットカテゴリの不均衡やロングテールの一般化をカバーし、データ増強やゼロショット評価補助に適しています。
- 軽量ベースライン:再現性実験の閾値を下げるために、0.8BスケールのDiT形状ベースライン(2048/4096トークン版)を提供します。
3. 設置
- 環境準備:Linux + Python(PyTorch/一般的なディープラーニングスタックを組み合わせて)を使用し、十分なディスク(約11TB、部分約5TB、合成ディスク約6.5TB)を予約することが推奨されます。
2. データの取得(推奨):Hugging Face CLIをインストールした後、hf downloadを使って全額またはサブセット単位でダウンロードします。
- ベースラインの再現:リポジトリをクローンし、ベースラインのディレクトリ記述に従って依存関係をインストールし、トレーニング/評価スクリプトを開始するためのデータパスの設定を行います。
4. 典型的なユースケース
- 3D生成トレーニングセット:拡散/GAN/自己回帰などの3D生成モデルの統一トレーニングデータソース。
- 単一/マルチビューから3Dへ:標準化されたレンダリング遠近法と幾何学的監督による再構築と評価。
- 編集と構造の一貫性を制御:コンポーネントレベルのグリッドとラベルを使って「パーツごとに生成/置き換え/再組み立て」を行う。
- ロボットおよびシミュレーションアセットライブラリ:部品分解を伴う手頃な価格の学習、把握計画、インタラクティブシミュレーションをサポートします。
- ロングテールとカテゴリーバランス:合成資産を用いて希少カテゴリーを完成させ、一般化比較実験の堅牢性と説明可能性を向上させる。
5. 生態系と競合製品
- 生態学:GitHubはデータ記述とベースラインコードを提供します。 Hugging Faceはデータセットのホスティングとベースラインの重みダウンロードを提供し、コミュニティの再現性を容易にしています。
- 競合製品/制御:一般的な3Dアセットライブラリや大規模な3Dデータセットで規模は十分ですが、ノイズ、構造の粒度の不足、評価のレベルの違いなどの問題が生じる可能性があります。 HY3D-Benchの違いは、「トレーニング準備済みクリーニング+コンポーネントレベルの構造+合成ロングテール完成+再現可能な軽量ベースライン」の組み合わせにあります。 実際のメリットとデメリットは、課題指標やアブレーション実験に基づいて推奨されます。
6. 制限事項と注意事項
- 高いストレージおよび帯域幅コスト:フルデータ量が大きいため、サブセット/オンデマンドごとに段階的にダウンロード・訓練することが推奨されます。
- ライセンスとコンプライアンス:データはマルチソースの処理や再配布から得られる場合があるため、各サブセットのリポジトリライセンスファイルおよびソース/配布指示を必ず読み、商業利用と再配布の境界を確認してください。
- コンポーネントラベリングの適用範囲:コンポーネントの定義や粒度はカテゴリによって異なるため、クラス横断一般化や構造的整合性評価を行う際には設計指標を慎重に設計する必要があります。
- 合成データバイアス:AIGC資産はスタイル分布の変化を引き起こす可能性があり、実数データミキシング比率やカテゴリ再サンプリング戦略と組み合わせてそれらを抑制することが推奨されます。
7. プロジェクトアドレス
https://github.com/Tencent-Hunyuan/HY3D-Bench
8. よくある質問
Q: HY3D-Benchデータセットにはどのようなサブセット(フルレベル/パーツレベル/合成)が含まれていますか?
A: フルレベルはレンダリング/サンプリングポイントを持つ252K+の完全な防水オブジェクトを提供します。 パーツレベルは240K+のパーツレベルの分解およびアセンブリレンダリングを提供します。 Syntheticは1,252の細かいサブクラスにわたり125K+の合成アセットを提供しています。
Q: スペースを節約するためにHY3D-Benchをダウンロードするにはどうすればいいですか?
A: Hugging Faceのper-pathインクォルテ方式を使って、full/**、part/**、またはsynthetic/**のみを取得し、小さなサブセットや検証セットから始めるのが望ましいです。
Q: Hunyuan3D-2.1-Small / Hunyuan3D-Shape-v2-1 Smallの基準線の関係は何ですか?
A: 論文ではHunyuan3D-2.1-Smallを実証検証に使用していることが挙げられています。 データページには、フルレベルのトレーニングに基づく軽量形状の基準重量(0.8B)も提供されています。 複製実験の設定は、リポジトリの基準説明に基づいて選択することを推奨します。
Q: パートレベルのデータは「パーツによって生成/編集」できますか?
A: トレーニングの監督および評価ベンチマーク(部品ラベル+パーツメッシュ+アセンブリレンダリング)として使用できますが、部品の定義やカテゴリの違いが制御可能な効果に影響を与え、タスク設計や指標と調整する必要があります。
Q: Syntheticサブセットは直接マスタートレーニングセットに適していますか?
A: より一般的な用途はロングテールを埋めてデータ強化を行うことです。 もしこれを主な訓練セットとして使う場合は、分布バイアスに注意を払い、対照実験では実部分集合と混同することが推奨されます。