一、摘要
LongCat-Flash-Lite 是一个以高稀疏 MoE 场景为目标的开源大模型:总参数 68.5B,但每 token 仅激活约 2.9B~4.5B。它的关键思路不是继续堆 MoE 专家数,而是在特定稀疏区间通过扩容 N-gram Embedding(约 30B+ 参数用于 embedding)取得更好的“效果-成本”折中,并配合系统侧优化提升推理吞吐。模型支持 256K 上下文(YaRN)。
二、核心特性
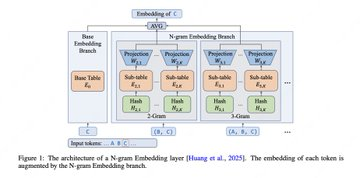
1、N-gram Embedding 扩容:在高稀疏 MoE 下,用更大的 N-gram embedding 表提升 Pareto 前沿表现。
2、推理效率优化:引入 N-gram Cache 与同步 kernel,降低 MoE 层 I/O 压力,面向低延迟与高吞吐。
3、Agentic/Coding 取向:在工具使用与编码类评测中表现突出(如 SWE-Bench、τ²-Bench、TerminalBench)。
4、长上下文:256K context window,适合代码仓库级输入与长对话任务分解。
三、安装
1、环境:Python≥3.10,Torch≥2.6,Transformers≥4.57.6,Accelerate≥1.10.0。
2、依赖安装:pip install -U transformers==4.57.6 accelerate==1.10.0
3、加载方式:使用 Transformers 加载,并开启 trust_remote_code=True(建议先审阅自定义代码再上生产)。
4、硬件提示:官方示例提到至少 2 张 80GB 显存 GPU(如 A100/H100 80GB)用于运行。
四、典型用例
1、代码代理:多文件改动、单测修复、PR 生成与迭代。
2、工具调用 Agent:函数/工具编排、工作流自动化、检索+执行闭环。
3、长上下文编码:大仓库阅读、长日志/长报错定位、跨模块追踪。
4、通用推理:在保持成本可控的前提下做日常问答与推理任务。
五、生态与竞品
1、生态:提供 Transformers 快速上手;并给出 SGLang 侧的适配与单机多卡并行(TP/EP)部署示例。
2、竞品参照:官方对比表中包含同为 MoE 的 Kimi-Linear-48B-A3B、Qwen3-Next-80B-A3B-Instruct,以及闭源的 Gemini 2.5 Flash-Lite;LongCat-Flash-Lite 的侧重点是“较低激活计算 + embedding 扩容 + 系统优化”的组合路线。
六、局限与注意事项
1、显存与带宽压力:embedding 参数占比高,可能更吃显存与内存带宽;不同硬件下收益会不一致。
2、trust_remote_code 风险:生产环境需代码审计与固定版本。
3、评测可复现性:部分对比项来自公开报告;实际效果应以你的数据、提示词与代理框架复测为准。
4、长上下文成本:256K 虽能装下更多信息,但检索、截断与提示工程仍决定最终稳定性与成本。
七、项目地址
https://huggingface.co/meituan-longcat/LongCat-Flash-Lite
八、常见问题
Q: LongCat-Flash-Lite 的 “N-gram Embedding” 解决了什么问题?
A: 目标是在高稀疏 MoE 场景里,用更大的 N-gram embedding 表提升表达与命中效率,从而在相近激活计算下获得更好的效果-成本折中。
Q: LongCat-Flash-Lite 为什么需要开启 trust_remote_code?
A: 因为模型包含自定义加载/推理逻辑;上生产前应锁定版本并审阅相关代码。
Q: LongCat-Flash-Lite 是否适合本地单卡?
A: 官方快速上手建议至少 2×80GB GPU;单卡需要更激进的量化/并行与工程改造,且不保证效果与稳定性。
Q: 256K 长上下文如何更稳地用在代码仓库?
A: 通常结合检索与分块(RAG/文件级索引)比“全量塞进上下文”更稳、更省成本。
Q: SGLang 部署 LongCat-Flash-Lite 的关键点是什么?
A: 重点是 TP/EP 组合并行与对应 kernel/依赖版本匹配;建议从官方给出的启动参数模板改起。