1. Conclusion des performances
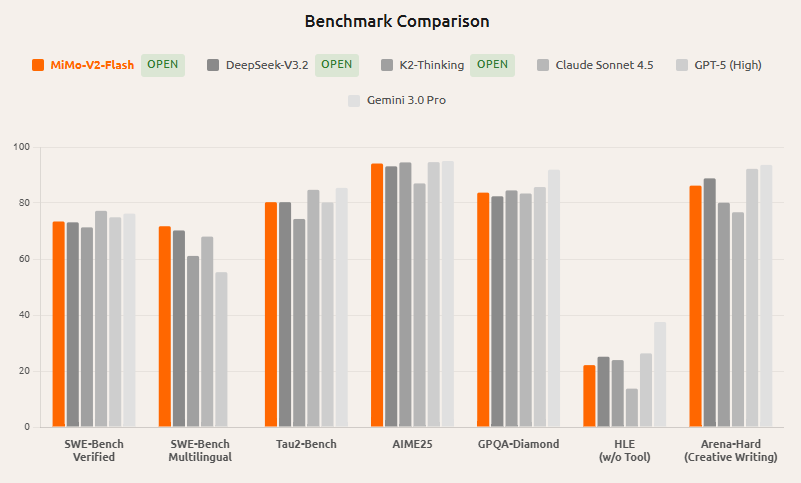
Dans la série Xiaomi MiMo, MiMo-V2-Flash adopte la voie de la « densité haute efficacité » : 309 Ko de paramètres totaux de l’architecture MoE et environ 15 Milliards de paramètres d’activation. Ses cartes modèles montrent de fortes performances sur plusieurs benchmarks généraux et d’inférence, avec des évaluations liées au code et aux agents particulièrement présentes.
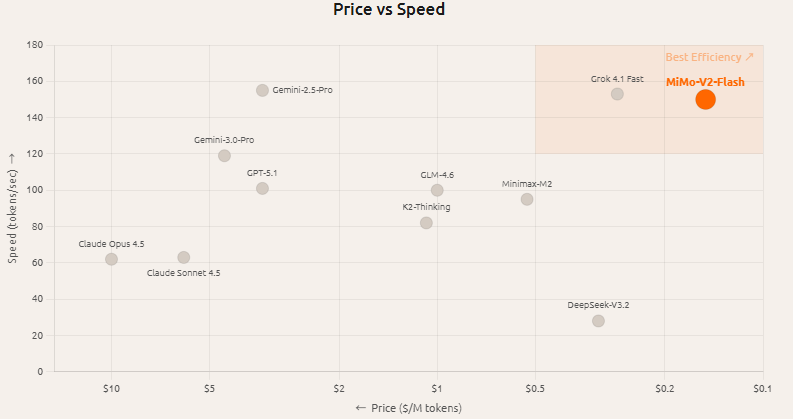
2. Vitesse et coût
Selonl’introduction officielle, il adopte une attention hybride, la prédiction multi-jetons et d’autres conceptions pour réduire la surcharge d’inférence, et fournit des contextes de 256k de long, ce qui est plus enclin aux appels d’outils multi-tours et aux scénarios de workflow.
3. Comment percevoir le benchmarking
De nombreuses interprétations tierces le comparent à des modèles open source haut de gamme tels que DeepSeek-V3.2 ; Cependant, la banque de questions de différentes listes, l’utilisation d’outils et les réglages de raisonnement sont très différents, et les scores ne doivent pas être directement égalisés, et il est recommandé de voir les résultats reproduits dans les mêmes conditions.
4. Suggestions d’atterrissage
Jugez si elle vous convient et utilisez votre propre ensemble de tâches pour hors ligne A/B : prêter attention au débit et à la latence, au taux d’hallucinations, au taux de réussite des outils et au coût unitaire ; Réévaluation sur site de la quantification, du parallélisme et de l’adéquation du cadre.
5. Questions fréquemment posées
Q&R Q : Le 309B est-il difficile à gérer ?
R : L’inférence s’active principalement vers 15B, mais un GPU/multi-carte puissant est toujours recommandé ; La quantification abaisse considérablement la barrière à l’entrée.
Q : Est-il préférable d’écrire du code ou de discuter ?
R : Le positionnement est davantage biaisé vers l’inférence, le codage et les flux de travail des agents ; Le style de chat pur et la stabilité doivent dépendre de votre mesure réelle de la scène.
Q : Existe-t-il des Mimo plus petits ?
R : Oui, MiMo a également publié le modèle orienté inférence 7B, adapté à la recherche légère et à la comparaison.