1. Performance conclusion
In the Xiaomi MiMo series, MiMo-V2-Flash takes the "high-efficiency density" route: 309B total parameters of the MoE architecture and about 15B activation parameters. Its model cards show strong performance on a number of general and inference benchmarks, with code and agent-related evaluations being particularly prominent.
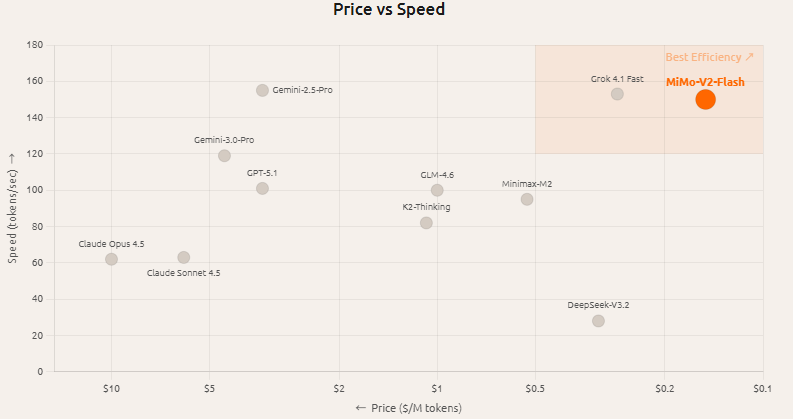
2. Speed and Cost
According tothe official introduction, it adopts hybrid attention, multi-token prediction and other designs to reduce inference overhead, and provides 256k long contexts, which is more inclined to multi-round tool calls and workflow scenarios.
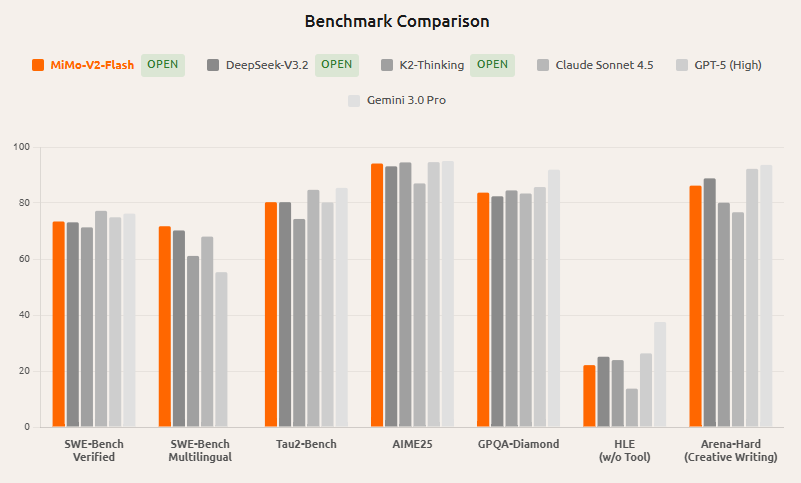
3. How to view benchmarking
Many third-party interpretations compare it with high-end open source models such as DeepSeek-V3.2; However, the question bank of different lists, whether tools are used, and reasoning settings are very different, and the scores should not be directly equalized, and it is recommended to see the results reproduced under the same conditions.
4. Landing suggestions
Judge whether it is "suitable for you" and use your own task set for offline A/B: pay attention to throughput and latency, hallucination rate, tool success rate and unit cost; On-premises re-evaluation of quantification, parallelism, and framework fit.
5. Q&A Frequently Asked Questions
Q: Is 309B difficult to run?
A: Inference is mainly activated at about 15B, but a strong GPU/multi-card is still recommended; Quantification significantly lowers the barrier to entry.
Q: Is it better to write code or chat?
A: Positioning is more biased towards inference, coding, and agent workflows; The pure chat style and stability should be subject to your actual measurement of the scene.
Q: Are there any smaller MiMos?
A: Yes, MiMo has also released the 7B inference-oriented model, which is suitable for lightweight research and comparison.