1. Éclaircissement de l’information de base
· Le modèle multimodal du monde EMU3.5 a été lancé par l’équipe de l’Institut de recherche en intelligence artificielle Zhiyuan de Pékin et constitue un modèle multimodal natif pour la modélisation unifiée de la vision et du langage. Se concentrer sur l’illumination · EMU3.5 offre à la fois une plateforme d’expérience web et des clients associés, facilitant l’utilisation directe des capacités de modèles pour les utilisateurs de recherches scientifiques, les développeurs d’entreprise et les créateurs de contenu.
Wujie · EMU3.5 se positionne comme une base de modèles mondiaux multimodals, qui combine modèles open source et expérience en ligne, en tenant compte de la reproductibilité de la recherche scientifique et de la facilité d’utilisation au niveau du produit, et fournit un support de base pour la génération de contenu multimodale et les applications liées à la modélisation mondiale.
2. Présentation du produit
Wujie · L’objectif principal d’EMU3.5 est d’atteindre des capacités unifiées de modélisation du monde, en traitant simultanément images et texte dans le même modèle, et en traitant les deux comme une séquence unifiée pour la modélisation et la génération. Les utilisateurs peuvent saisir soit du texte brut, soit un mélange de graphiques et de texte, permettant au modèle de produire des images, du texte ou du contenu entrelacé.
Pour les utilisateurs ordinaires, Wujie · Emu3.5 propose une page d’expérience web qui intègre des fonctions telles que l’espace de travail d’auteur, la présentation de cas et la gestion de l’historique, permettant la génération rapide de texte d’images, la retouche d’images et la création de graphiques. Pour les utilisateurs techniques et scientifiques, les modèles peuvent être déployés localement ou sur des serveurs via des dépôts open source pour expérimentation et développement secondaire.
3. Fonctions principales
1. Fonctions principales
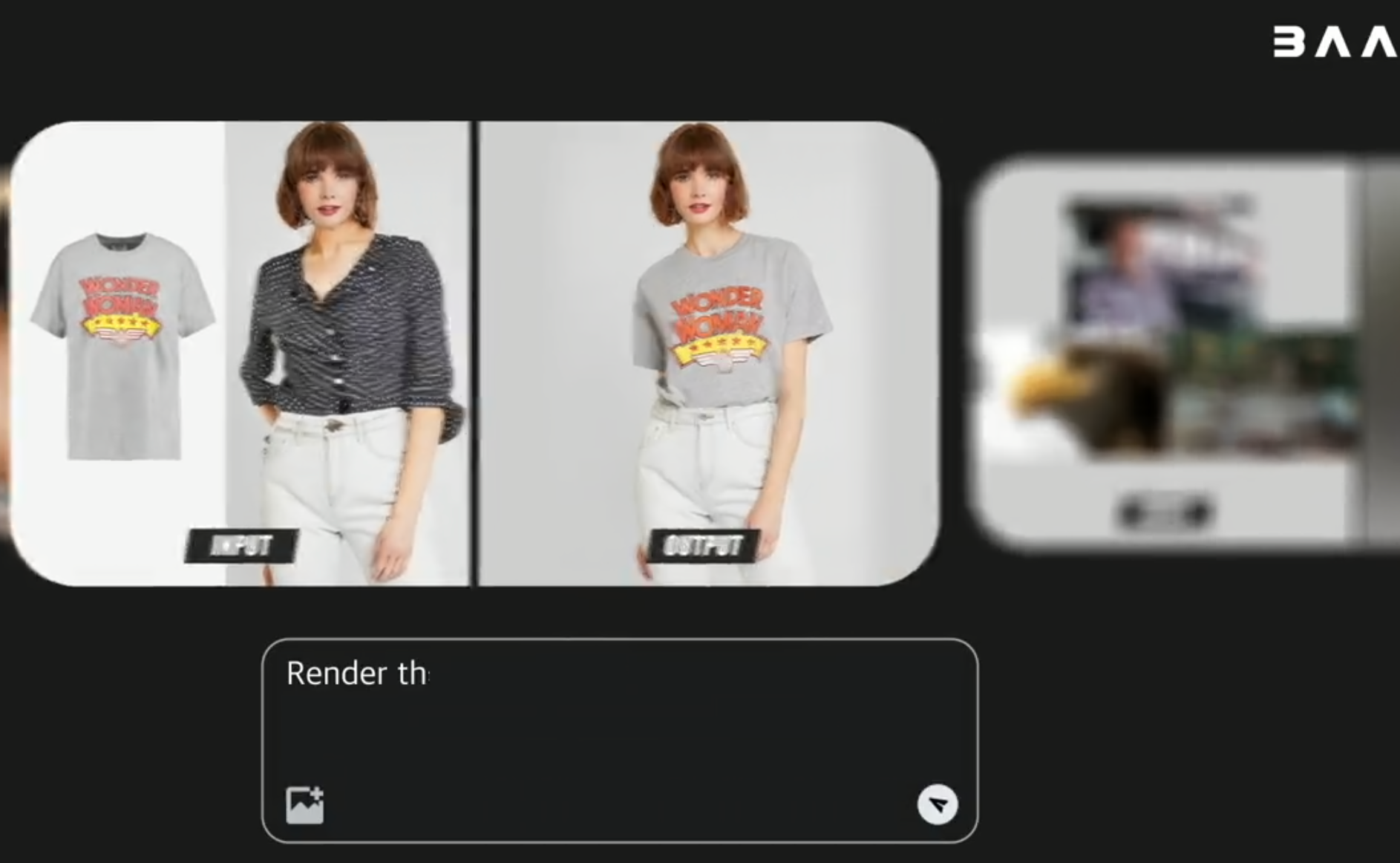
- Les images de génération de texte permettent
- de générer des images de haute qualité basées sur des descriptions en langage naturel, adaptées à des scénarios créatifs tels que des illustrations, des illustrations et des croquis d’affiches.
- Arbitrary to Image Generation
- permet la génération conjointe d’images et de texte graphique, et le transfert de style, le remplacement d’éléments et l’ajustement de la mise en page sont effectués tout en préservant la structure principale.
- La retouche et la restauration d’images
- peuvent effacer, remplacer et améliorer certaines parties de l’image pour des tâches de retouche telles que la modification des détails, l’ajout d’objets et l’ajustement de l’arrière-plan.
- Génération de contenu entrelacé
- Générez des séquences de contenu composées de plusieurs images et descriptions textuelles correspondantes, adaptées aux récits visuels, aux descriptions tutoriels et aux présentations en plusieurs étapes.
2. Caractéristiques techniques
du monde · EMU3.5 adopte une méthode unifiée de modélisation de séquences pour unifier les marqueurs visuels et textuels afin de former un cadre multimodal natif de bout en bout. Le modèle est entraîné sur des données multimodales à grande échelle, en se concentrant sur de longues vidéos et leurs descriptions textuelles afin d’apprendre la continuité spatio-temporelle et la structure dynamique du monde.
Au stade d’inférence, le modèle fournit une solution d’accélération pour les tâches de génération d’images, en tenant compte de la qualité et de l’efficacité de la génération, et convient à une utilisation dans des environnements de recherche scientifique et des prototypes de produits.
4. Scénarios applicables et compréhension de la foule
· Le modèle multimodal du monde EMU3.5 convient aux populations et scénarios suivants :
- Recherche et enseignement : Les universités et institutions de recherche sont utilisées pour l’apprentissage multimodal, la modélisation du monde, la compréhension et la génération vidéo, ainsi que d’autres orientations de recherche et d’expériences de programme.
- Création et conception de contenu : Les illustrateurs, designers et équipes de nouveaux médias l’utilisent pour générer rapidement des croquis créatifs, des cartes d’ambiance et des supports graphiques, améliorant ainsi l’efficacité de la production de contenu.
- Développement et innovation produit : l’équipe technique de l’entreprise va Wujie · EMU3.5 est utilisé comme modèle sous-jacent pour construire des assistants multimodaux, des outils de génération de vision ou des applications d’agents avec des capacités de compréhension graphique.
5. Foire
aux questions Q : Illumination · Quel est le positionnement central du modèle multimodal du monde EMU3.5 ?
R : L’Illumination · La position centrale d’EMU3.5 est d’unifier la base de modèles multimodaux mondiaux pour modéliser la vision et le langage, et de fournir des capacités multimodales unifiées pour la recherche scientifique, les expériences et le développement d’applications grâce à la combinaison de modèles open source et de plateformes en ligne.
Q : L’Éveil · À qui la plateforme web EMU3.5 est-elle principalement adaptée ?
R : L’Illumination · La plateforme web EMU3.5 est principalement destinée aux créateurs de contenu, designers, équipes de nouveaux médias et utilisateurs ordinaires ayant besoin de création multimodale, et est utilisée pour des tâches telles que la génération de texte d’images, la retouche d’images et la création de contenu graphique.
Q : L’Éveil · EMU3.5 supporte-t-il le développement sur site et secondaire ?
R : L’Illumination · EMU3.5 fournit du code open source et des poids de modèles pouvant être déployés sur site ou en environnement serveur, permettant aux développeurs de mener des recherches, des tests et du développement secondaire tout en respectant les termes de licence open source pertinents.



