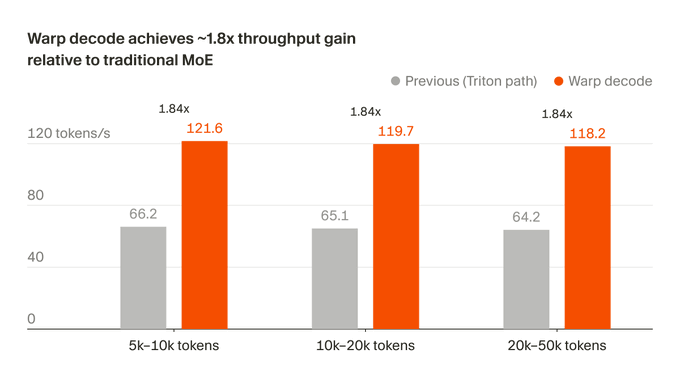
Cursor a récemment révélé qu 'il a reconfiguré le chemin de génération de jetons du modèle MoE sur le GPU et a nommé cette méthode décodage de warp. L'optimisation sous-jacente a permis une augmentation du débit d'inférence de 1,84 fois, tout en rapprochant la sortie de la valeur de référence du FP32, et les améliorations ont également été utilisées dans le processus de formation du compositeur pour accélérer les itérations du modèle et la publication de version.
Cursor a réécrit le décodage de MoE
Le cœur de cette mise à jour n'est pas simplement un GPU plus rapide pour le modèle, mais une réécriture de la façon dont MoE décode sur Blackwell. Alors que le schéma traditionnel organise les calculs en experts, le curseur inverse l'axe parallèle sur les sorties, laissant chaque warp responsable d'une valeur de sortie au lieu de tourner autour de la route d'expert.
Cet ajustement cible les scénarios de décodage en petits lots. Lorsque le modèle MoE génère un seul jeton, il y a beaucoup d'étapes qui sont consommées à l'organisation des données, à la manipulation et au tampon intermédiaire, et le pourcentage réel utilisé pour le calcul n'est pas élevé. Le but du décodage de warp est de supprimer ces liens supplémentaires autant que possible.
1.84x plus de vitesse est derrière le raccourcissement des liens d'inférence
Selon Cursor, le décodage de warp comprime toute la couche de calcul MoE en deux noyaux : _ _ CODE_INLINE_0 _ _ et _ _ CODE_INLINE_1 _ _. Le chemin d'inférence est plus court que les scénarios traditionnels centrés sur les experts, sans compter sur plusieurs étapes, la synchronisation à travers les warps et les tampons supplémentaires. Plus important encore, cette optimisation ne s'arrête pas à « plus vite ». Dans le même temps, le fonctionnaire souligne que les résultats de sortie sont plus proches de la valeur de référence FP32, ce qui rend le décodage de warp non seulement une optimisation du débit, mais aussi plus comme une reconstruction sous-jacente qui tient compte des performances numériques. Pour les modèles de génération de code, la stabilité est souvent aussi importante que la vitesse. Le curseur a lié cette mise à jour directement à Composer dans la représentation originale. La logique officielle est claire : les données de pré - formation et les RL déterminent les limites supérieures du modèle, mais l'efficacité des liens d'inférence affecte la vitesse à laquelle la recherche, la formation et les commentaires de validation se déroulent, ce qui affecte le rythme des mises à jour de la version de Composer. La réécriture du décodeur MoE autour des GPU Blackwell montre que la concurrence des grands modèles revient à l'efficacité de l'exécution inférieure. Cursor ne parle pas de plus grande échelle de paramètres cette fois-ci, mais se concentre sur le débit, la précision et la vitesse d'itération. Pour Composer, la capacité de ces optimisations au niveau du système à se traduire en mises à jour plus rapides est probablement plus intéressante qu 'un changement de nommage de version unique.Composer commence à manger le dividende de l'optimisation au niveau système
Cela explique également pourquoi le curseur met l'accent uniquement sur ce travail d'ingénierie. Pour les entreprises d'IA, l'optimisation du noyau sous-jacent n'est pas seulement une amélioration de l'infrastructure ; elle affecte à son tour la vitesse de développement du modèle, la fréquence de publication et, finalement, l'expérience livrée aux développeurs.



