1. Zusammenfassung
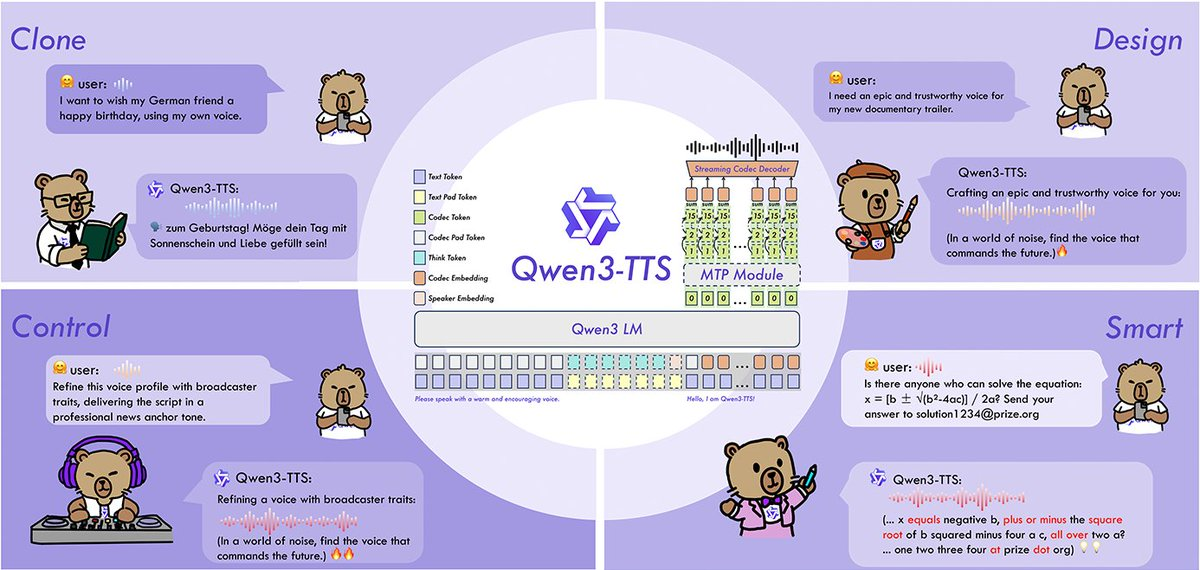
Qwen3-TTS ist eine Familie von Open-Source-Text-zu-Sprache (TTS)-Modellen aus dem Qwen-Team, darunter VoiceDesign (zur Erzeugung neuer Stimmen aus Textbeschreibungen), CustomVoice (Befehlssteuerung vorbestimmter hochwertiger Sounds) und Base (schnelles Voice-Cloning und Feinabstimmung der Basis). Das Projekt ist sowohl Code als auch Weight Open Source und stellt einen 12Hz-Sprachtokenizer bereit, um höhere Kompressions- und Streaming-Synthesefähigkeiten für Echtzeitgespräche, Synchronisation und personalisierte Sprachszenarien zu erreichen.
2. Kernmerkmale
1. Vollständige Familienabdeckung: VoiceDesign (kostenloses Sprachdesign), CustomVoice (benutzerdefinierte Klangfarbe- und Stilsteuerung), Base (3-sekündiges schnelles Klangfarbe-Klonen, kann für vollständige Feinabstimmung verwendet werden).
2. Zwei Maßstäbe: Die veröffentlichten Modelle decken etwa 0,6 Milliarden und 1,7 Milliarden Parameter ab (einige Werbekaliber werden als etwa 1,8 B angegeben, es wird empfohlen, sich auf die Lager- und Modellkartenbeschriftung zu beziehen).
3. 10 Sprachunterstützung: Chinesisch, Englisch, Japanisch, Koreanisch, Deutsch, Französisch, Russisch, Portugiesisch, Spanisch, Italienisch und bietet mehrere Dialekt-/Klangfarbekonfigurationen.
4. 12Hz-Tokenizer-Hochkompression: drückt Sprache bei einer niedrigeren Tokenfrequenz aus, reduziert die Bandbreiten- und Inferenzbelastung und eignet sich für Streaming und Offline-Synthese.
5. Kontrollierbar und robust: Unterstützung der Verwendung natürlicher Sprachbefehle zur Steuerung von Sprachgeschwindigkeit, Emotion, Prosodie usw., wodurch die Stabilität bei verrauschtem Text und komplexen Eingaben verbessert wird.
6. Vollständiger Feinabstimmungspfad: Das Lager stellt Feinabstimmungskataloge und Beispiele zur Verfügung, was für Branchenkorpus, Markentimbre oder spezifische Akzentanpassungen praktisch ist.
3. Installation
- Python-Umgebung: Es wird empfohlen, eine neue virtuelle Umgebung für Python 3.12 zu erstellen.
2. Ein-Klick-Installation: Direkt das PyPI-Paket installieren qwen-tts; Wenn lokale Änderungen erforderlich sind, klonen Sie das Repository und pip install -e . es.
- Ressourcenoptimierung: Die offizielle Empfehlung lautet, FlashAttention 2 zu installieren, um den Speicherverbrauch zu reduzieren. Gewichte können auch lokal über Hugging Face / ModelScope vorinstalliert werden.
4. Typische Anwendungsfälle
- Produkt-/Kundenservice-Sprache: Streaming-Übertragungen mit niedriger Latenz, angepasst an Konversationsassistenten und Echtzeit-Simultaninterpretation.
- Inhaltserstellung und Synchronisation: Verwenden Sie Befehle, um Emotionen und Sprachgeschwindigkeit zu steuern, um eine mehrstilige Erzählung zu erzeugen.
- Personalisierte Stimme: 3 Sekunden Referenzaudio zum Klonen des Timbre, verwendet als persönlicher Assistent oder barrierenfreies Lesen (Autorisierung erforderlich).
- Spiele und virtuelle Menschen: VoiceDesign generiert schnell Charakterklangfarben durch Textbeschreibungen und überlagert dann Stilsteuerungen.
- Feinabstimmung der Branche: Verwenden Sie den eigenen Korpus für vollständige Feinabstimmung, um das Lesen von Terminologie, Akzentkonsistenz und die Stabilität des Markentimbrons zu verbessern.
5. Ökologie und konkurrierende Produkte
- Ökosystem: Bereitstellung von Hugging Face/ModelScope-Modellsammlung und Online-Demo; Unterstützt nativ den Start der Web-UI; Gleichzeitig werden API-Dokumentationen zu DashScope/Model Studio bereitgestellt; Und erwähnte die Integrationsrichtung von vLLM-Omni.
- Konkurrenzprodukte: Gängige Lösungen auf der Open-Source-Seite sind Coqui TTS, Bark, XTTS, StyleTTS2 usw., mit Fokus auf Mehrsprachigkeit, Klonqualität, Kontrollierbarkeit und Bereitstellungskosten. Der Unterschied von Qwen3-TTS liegt mehr in der Integration von "Sprachdesign + Klonen + Streaming mit niedriger Latenz + 12Hz-Hochkompressions-Tokenizer + Feinabstimmungslink".
6. Einschränkungen und Vorsichtsmaßnahmen
- Rechenleistung und Videospeicher: Größere Modelle und hochwertige Ausgaben verbrauchen in der Regel mehr GPU; Streaming-Dienste müssen außerdem auf Nebenläufigkeit und Latenz-Jitter achten.
- Klangfarbe-Compliance: Klangfarbenklonen und Onomatopoesie können Porträtrechte/Tonrechte und Inhaltscompliance beinhalten, daher sollten Sie eine Genehmigung einholen und die Nutzungsgrenzen gut einhalten.
- Qualitätsgrenze: Ausspracheabweichungen und Prosodieinstabilität können weiterhin in verschiedenen Sprachen, Akzenten, extremen Emotionen oder ultralangen Texten auftreten, daher wird empfohlen, manuelles Sampling und Nachbearbeitung hinzuzufügen.
- Produktionsbereitstellung: Browser-Mikrofonberechtigungen, HTTPS, Gateway- und Zertifikatskonfiguration beeinflussen die Verfügbarkeit der Demo/des Dienstes und müssen gemäß den offiziellen Anweisungen gehandhabt werden.
7. Projektadresse
https://github.com/QwenLM/Qwen3-TTS
8. Häufig gestellte Fragen
F: Welche Sprachen und Stimmen unterstützt Qwen3-TTS?
A: 10 Sprachen werden behandelt und mehrere Dialekt-/Klangfarbenkonfigurationen sind verfügbar; Die genauen Details unterliegen der Modellkarte und der Lagerbeschreibung.
F: Was ist der Unterschied zwischen Qwen3-TTS' VoiceDesign und Voice Clone?
A: VoiceDesign beschreibt das "Design" eines neuen Klangs in Worten; Voice Clone repliziert den Timbre des Zielsprechers mit einem kurzen Referenzton, zum Beispiel 3 Sekunden.
F: Welchen Wert hat der Qwen3-TTS 12Hz Tokenizer?
A: Die Expression von Voice-Tokens mit niedrigerer Frequenz kann eine höhere Kompression und ein geringeres Latenzpotenzial bieten, geeignet für das Streaming von Echtzeit-Synthese und Kostenkontrolle.
F: Kann Qwen3-TTS Feinabstimmung sein?
A: Ja, das Lager stellt Feinabstimmungscodes und Beispielprozesse bereit, was sich für die Anpassung von Industriekorpus und Markenton eignet.
F: Wie erlebt Qwen3-TTS die Demo schnell?
A: Du kannst die Online-Demo Hugging Face/ModelScope verwenden oder nach der lokalen Installation qwen-tts den offiziellen Web-UI-Befehl starten, um es zu erleben.



