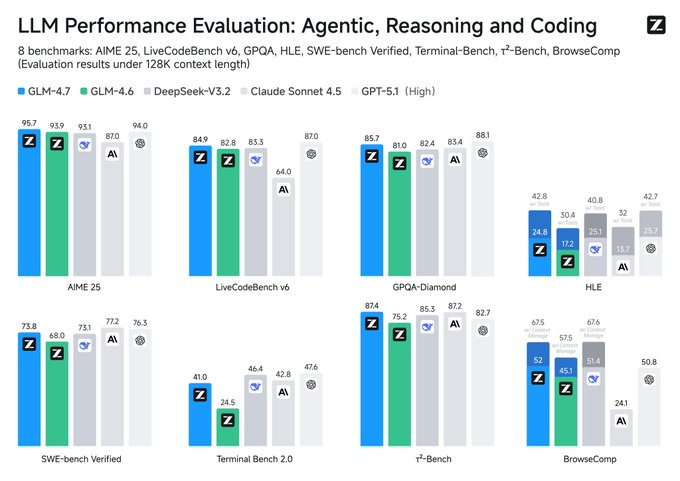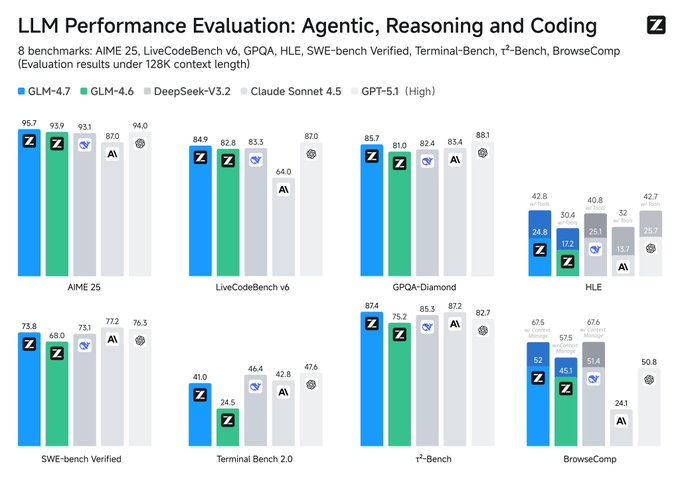
1. Résumé
GLM-4.7 est un modèle de langage open source axé sur les droits et publié par zai-org. Selon les informations officielles, il a considérablement amélioré les capacités de codage, le raisonnement complexe et l’utilisation d’outils à étapes multiples par rapport à GLM-4.6, et améliore également la performance de scénarios généraux tels que le dialogue, l’écriture créative et le jeu de rôle. L’effet réel sera affecté par l’invite, la stabilité de la chaîne d’outils et la configuration du déploiement, il est donc recommandé de réaliser une évaluation de régression basée sur vos tâches réelles.
2. Caractéristiques principales
- Les capacités de programmation intelligente par asana sont renforcées : une plus grande importance est accordée à la boucle fermée de compréhension des exigences, de désassemblage des tâches, de vérification d’exécution et de réparation itérative.
- Amélioration du raisonnement complexe : Pour le raisonnement en plusieurs étapes, les tâches et contraintes à liens longs sont plus robustes (sous réserve de la description officielle).
- Utilisation plus mature des outils : Il est plus adapté au flux de travail consistant à « réaliser des tâches avec des outils » telles que les appels de fonctions, les opérations de terminal, et la récupération/navigation.
- Le mode de pensée est plus contrôlable : offre une variété de modes de réflexion pour équilibrer stabilité, latence et style de sortie.
- Optimisation de la qualité de la génération : Les dialogues sont plus naturels, et la cohérence entre l’écriture créative et le jeu de rôle est meilleure (sous réserve de la description officielle).
3. Installation
- Télécharger les poids : Obtenez les poids des modèles, les configurations et les descriptions d’exemples sur Hugging Face.
- Choisissez un cadre d’inférence : Vous pouvez utiliser vLLM, SGLang ou Transformers pour l’inférence locale et le déploiement.
- Préparer l’environnement d’exploitation : les grands modèles ont des exigences élevées en mémoire vidéo, disque et bande passante ; Des stratégies telles que la quantification, le parallélisme et la mise en cache peuvent être adoptées pour réduire les coûts et augmenter le débit (sous réserve des pratiques officielles et communautaires).
4. Cas d’usage typiques
- Génération et réparation de code : générer des correctifs, compléter des fonctions, positionner des erreurs, lancer des tests et réparer de manière itérative.
- Automatisation des terminaux : dépannage environnemental, analyse des journaux, gestion des conflits de dépendances et exécution par lots de scripts.
- Agent d’orchestration d’outils : recherche de chaînes, base de données, système de tickets, CI/CD et autres outils dans un processus en plusieurs étapes.
- Génération front-end et de contenu : Produire rapidement la structure de la page, les styles de composants et les brouillons de présentation pour faciliter la vérification du prototype.
5. Écologie et produits concurrents
- Écosystème : Fournir des portails d’expériences en ligne, des plans de codage par abonnement, ainsi que des blogs de poids et techniques pour faciliter l’essai jusqu’au déploiement local.
- Produits concurrents : des modèles open source et fermés similaires mettent leur propre accent sur le codage, le raisonnement et l’utilisation des outils ; Lors de la sélection, il est recommandé de vous fier à vos données, à votre véritable chaîne d’outils et au script d’évaluation, plutôt que de simplement consulter une seule liste ou un seul résultat affiché.
6. Limitations et précautions
- Puissance de calcul et coût : Le volume du modèle est important, et le déploiement local doit évaluer la mémoire vidéo et le débit. Des contextes longs et des résultats longs peuvent encore amplifier la consommation de ressources.
- Sécurité des outils : Lors de l’exécution de commandes terminales, de navigation et d’API externes, il faut bien faire un travail sur l’isolation des privilèges, l’audit, le délai d’attente et les politiques de réessayage.
- Fiabilité et vérification : Les codes clés et les conclusions doivent encore être testés individuellement, vérifiés statiquement et examinés manuellement pour éviter des erreurs causées par des hallucinations ou des conditions aux limites.
7. Adresse du projet
http://huggingface.co/zai-org/GLM-4.7
8. Questions fréquemment posées
Q : Où puis-je télécharger les poids GLM-4.7 ?
R : Téléchargez les poids et les fichiers de configuration depuis la page zai-org/GLM-4.7 de Hugging Face.
Q : Comment puis-je expérimenter le GLM-4.7 en ligne (chat.z.ai) ?
R : Expérience de conversation en ligne avec chat.z.ai.
Q : Comment puis-je activer le modèle par défaut du plan de codage GLM-4.7 (z.ai/subscribe) ?
R : Suivez les instructions sur la page d’abonnement pour sélectionner un package et compléter la configuration.
Q : Quelles méthodes de déploiement sur site (vLLM/SGLang/Transformers) GLM-4.7 prend-il en charge ?
R : Il peut généralement être déployé via vLLM, SGLang, Transformers et d’autres frameworks, et les étapes spécifiques dépendent de la page modèle et des exemples de documentation officielle.
Q : À quoi sert le mode de réflexion du GLM-4.7 ?
R : Il est utilisé pour améliorer la planification et la stabilité des tâches en plusieurs étapes ; Les modes différents ont des compromis en termes de latence et de style de sortie, il est donc recommandé de choisir selon l’expérience de tâche.