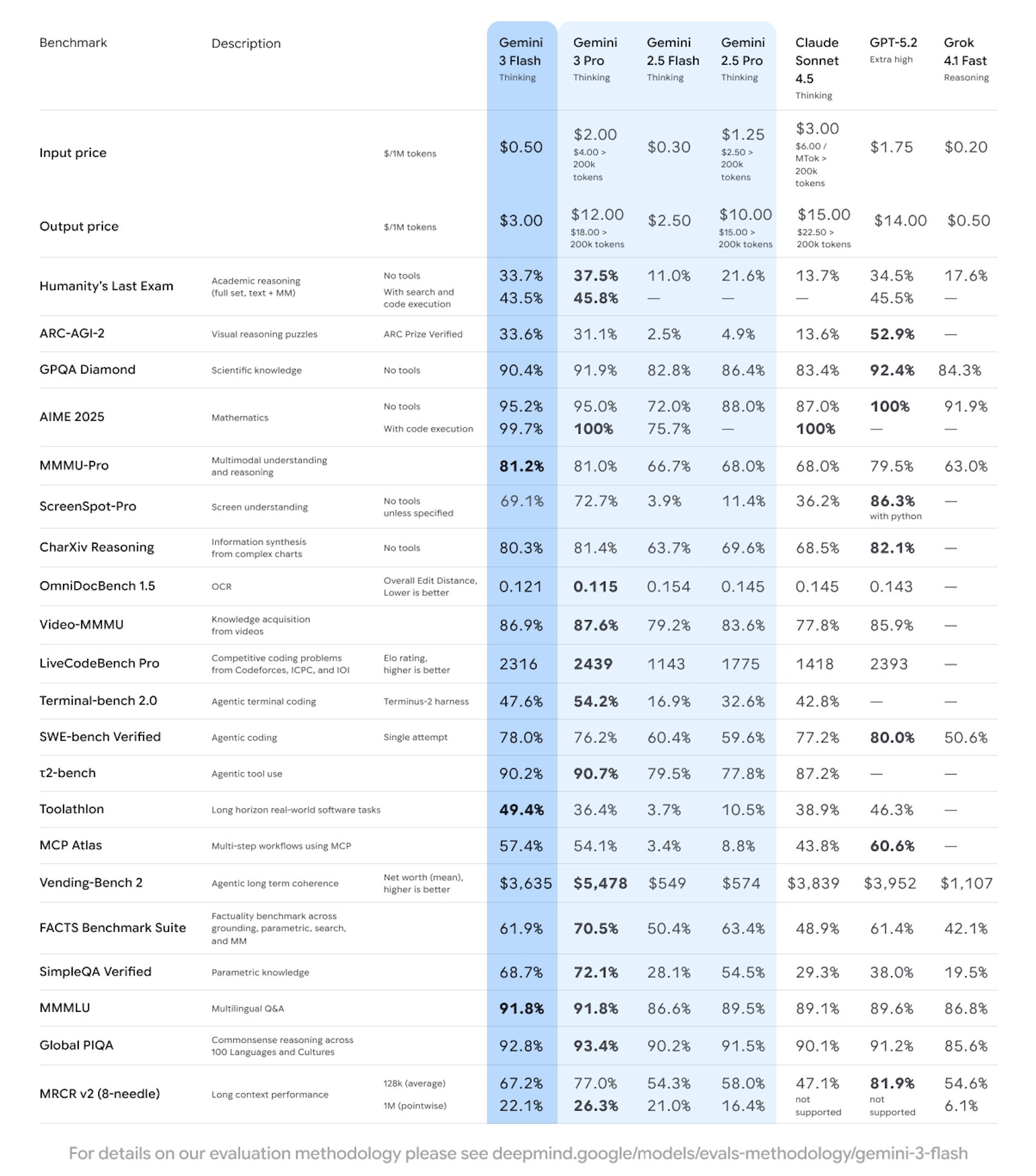
Google kündigte die Einführung einer neuen Generation leichter, moderner Modelle, Gemini 3 Flash an, die sich auf hohe Geschwindigkeit, niedrige Latenz und großflächige Verfügbarkeit konzentriert und offiziell in den meisten Bewertungen angibt, dass sie stärker als Gemini 2.5 Pro ist und die Codierungs- und Toolaufruffunktionen deutlich stärkt. Das Modell wurde in Gemini API/AI Studio, Vertex AI und Gemini CLI vorgestellt und gleichzeitig in einigen Produktszenarien aktiviert. Die Preisgestaltung beträgt 0,50 $ pro Eingabe von Token und 3,00 $ pro Ausgabe von Token (einschließlich Thinking Tokens).
Laut der offiziellen Einführung optimiert Gemini 3 Flash Durchsatz und Kosten, während es Inferenz- und multimodale Verständnisfähigkeiten beibehält, was es für Anwendungen mit hoher Nebenläufigkeit und Agenten-Workflows geeignet macht. Unternehmen und Entwickler können bei Bedarf auf "Geschwindigkeit/Tiefe" abwechseln. Die aktuelle Version befindet sich in der Vorschau, und Kapazität und Quote können im Verlauf der Veröffentlichung angepasst werden. Die regionale Verfügbarkeit, Tarifbegrenzung und Abrechnungsregeln der verschiedenen Plattformen unterliegen den tatsächlichen Regeln jeder Plattform. Einige Premium-Funktionen oder höhere Quoten erfordern ein Abonnement oder eine Aktivierung des entsprechenden Dienstes.
FAQ
F: Was ist Gemini 3 Flash und auf welche Szenarien richtet es sich?
A: Es handelt sich um ein Hochgeschwindigkeits- und effizientes Modell der Gemini-3-Serie, geeignet für Szenarien mit niedriger Latenz wie Coding, Werkzeugaufrufe und multimodale Inferenz.
F: Wie schneidet der Gemini 3 Flash im Vergleich zum 2.5 Pro ab?
A: Beamte und mehrere Bewertungen sagen, dass es bei den meisten Indikatoren stärker ist und bei Aufgaben wie Proxy-Codierung besser abschneidet.
F: Wie ist die Preis- und Abrechnungsmethode?
A: Geben Sie 0,50 $ pro Million Token ein, geben Sie 3,00 $ pro Million aus, und der Ausgabepreis beinhaltet Thinking Tokens.
F: Wie benutzt man es jetzt?
A: Es kann in Form von "Preview" in der Gemini API, AI Studio, Vertex AI und Gemini CLI aufgerufen werden, wobei die spezifische Quote und Region je nach Plattform abhängen.
F: War es vollständig und stabil?
A: Dies befindet sich derzeit in der Vorschau, und Kapazität, Limit und Verfügbarkeitsbereich können noch angepasst werden.



