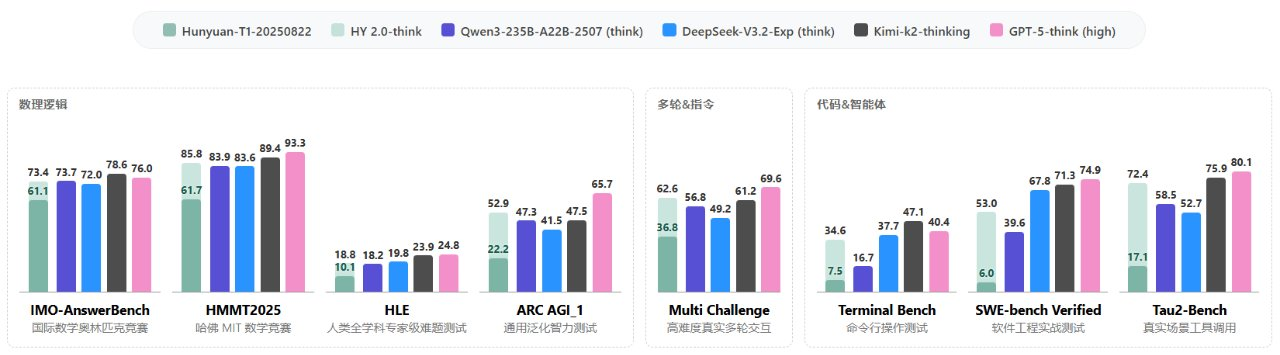
The Tencent Hunyuan team announced the official release of the latest version of the language model, Tencent HY 2.0, which is open to developers and enterprises through Tencent Cloud API. This upgrade adopts a hybrid expert (MoE) architecture with a total parameter scale of 406 billion, activation parameters of 32 billion, and supports a maximum of 256K context windows, which is significantly improved in mathematical reasoning, code generation, and complex task execution compared to the previous generation model. According to the official introduction, HY 2.0 scored 73.4 points on IMO-AnswerBench, and its score on agent tasks such as SWE-bench Verified and Tau2-Bench also jumped significantly.
HY 2.0 provides two types of optimized versions: Tencent HY 2.0 Think is aimed at deep reasoning, code generation, and complex instruction scenarios, and the cloud interface currently supports a maximum input of 128K and output of 64K, focusing more on long texts, multi-round dialogues, and difficult reasoning capabilities; Tencent HY 2.0 Instruct is aimed at daily conversations, creation, and high-concurrency services, with a maximum input of 128K and an output of 16K, emphasizing responsiveness and universal stability. In terms of training strategy, the official emphasizes the introduction of RLVR + RLHF dual-stage reinforcement learning, and balances "thinking depth" and generation efficiency through length penalty and task sandbox design.
At present, HY 2.0 has been connected to its own applications such as Tencent Yuanbao, and provides API calls and enterprise access capabilities on Tencent Cloud. The specific price, current limiting strategy and more technical details are still subject to Tencent Cloud's official documentation, and the original data of some internal benchmarks has not yet been fully disclosed, and the external performance comparison is mainly based on the indicators and instructions released by Tencent.
FAQ
Q: What is Tencent HY 2.0?
A: It is the latest generation of Tencent Hunyuan's general-purpose large language model, using MoE architecture, with total parameters of 406B and activation of 32B, focusing on reasoning, code and long text capabilities.
Q: What are the specific versions of this release?
A: There are two main types of text models: Tencent HY 2.0 Think (for deep reasoning) and Tencent HY 2.0 Instruct (for general dialogue and authoring).
Q: What are the context length and input/output specifications of HY 2.0?
A: The family model claims to support up to 256K context, and the current maximum input of the cloud Think/Instruct interface is 128K, of which the maximum output of Think is 64K and the maximum output of Instruct is 16K.
Q: What is the main difference between Think and Instruct?
A: Think is more suitable for "slow thinking" tasks such as complex reasoning, code generation, and agent tool calls. Instruct is better suited for chat, writing, and business Q&A scenarios with high concurrency and high response requirements.
Q: Is it completely open source, how to access and use it?
A: HY 2.0 currently provides commercial services in the form of Tencent Cloud API, and has been implemented in some Tencent products.



