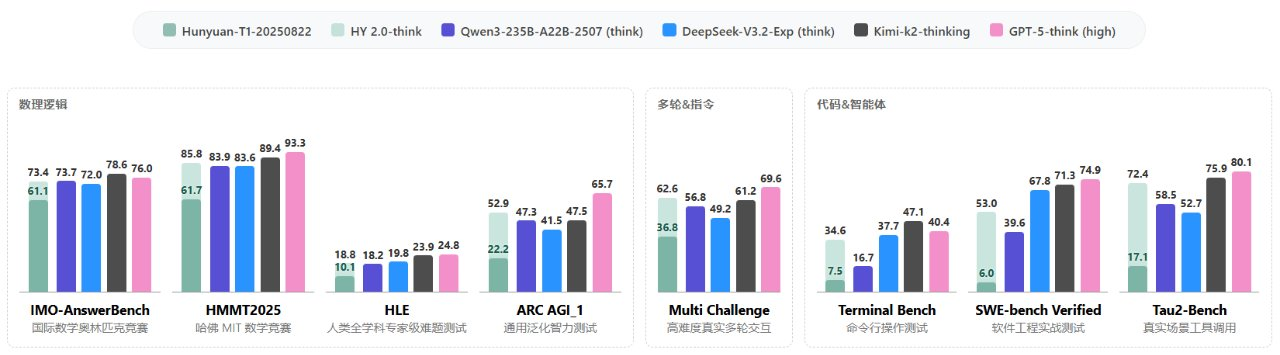
腾讯混元团队宣布最新版语言模型 Tencent HY 2.0 正式发布,并通过腾讯云 API 面向开发者和企业开放。此次升级采用混合专家(MoE)架构,总参数规模 4060 亿、激活参数 320 亿,支持最长 256K 上下文窗口,相比上一代模型在数学推理、代码生成与复杂任务执行方面均有明显提升。官方介绍称,HY 2.0 在 IMO-AnswerBench 上取得 73.4 分,在 SWE-bench Verified 与 Tau2-Bench 等智能体任务上的得分也大幅跃升。
HY 2.0 提供两类优化版本:Tencent HY 2.0 Think 面向深度推理、代码生成和复杂指令场景,云端接口当前支持最大输入 128K、输出 64K,更侧重长文、多轮对话与高难度推理能力;Tencent HY 2.0 Instruct 面向日常对话、创作和高并发业务,最大输入同为 128K、输出 16K,强调响应速度与通用稳定性。在训练策略上,官方强调引入 RLVR + RLHF 双阶段强化学习,并通过长度惩罚与任务沙盒设计平衡“思考深度”和生成效率。
目前,HY 2.0 已接入腾讯元宝等自家应用,并在腾讯云提供 API 调用和企业接入能力。具体价格、限流策略及更多技术细节仍以腾讯云官方文档为准,部分内部基准测试的原始数据尚未完全公开,对外性能对比主要基于腾讯方面公布的指标和说明。
常见问题
Q:Tencent HY 2.0 是什么?
A:它是腾讯混元最新一代通用大语言模型,采用 MoE 架构,总参数 406B、激活 32B,主打推理、代码与长文本能力。
Q:本次发布具体有哪些版本?
A:主要为两类文本模型:Tencent HY 2.0 Think(深度推理向)和 Tencent HY 2.0 Instruct(通用对话与创作向)。
Q:HY 2.0 的上下文长度和输入输出规格如何?
A:家族模型宣称最长支持 256K 上下文,目前云端 Think / Instruct 接口最大输入为 128K,其中 Think 最大输出 64K,Instruct 最大输出 16K。
Q:Think 和 Instruct 的主要区别是什么?
A:Think 更适合复杂推理、代码生成、Agent 工具调用等“慢思考”任务;Instruct 更适合高并发、响应要求较高的聊天、写作和业务问答场景。
Q:是否已经完全开源,如何接入使用?
A:HY 2.0 当前以腾讯云 API 形式提供商用服务,并已在部分腾讯系产品落地,模型权重尚未公开,接入需通过腾讯云控制台开通相关大模型服务。



