Qwen3-Omni combines multimodal AI with end-to-end reasoning: a single model unifies the input and output of text, images, audio, and video, balancing speed and accuracy. In public testing, Qwen3-Omni achieved leading results on a wide range of audio and video benchmarks, and offers a variety of available weights, making it suitable for quick adoption and further development.
1. Why is “end-to-end multimodal AI” important?
1. Truly unified multimodal AI capabilities
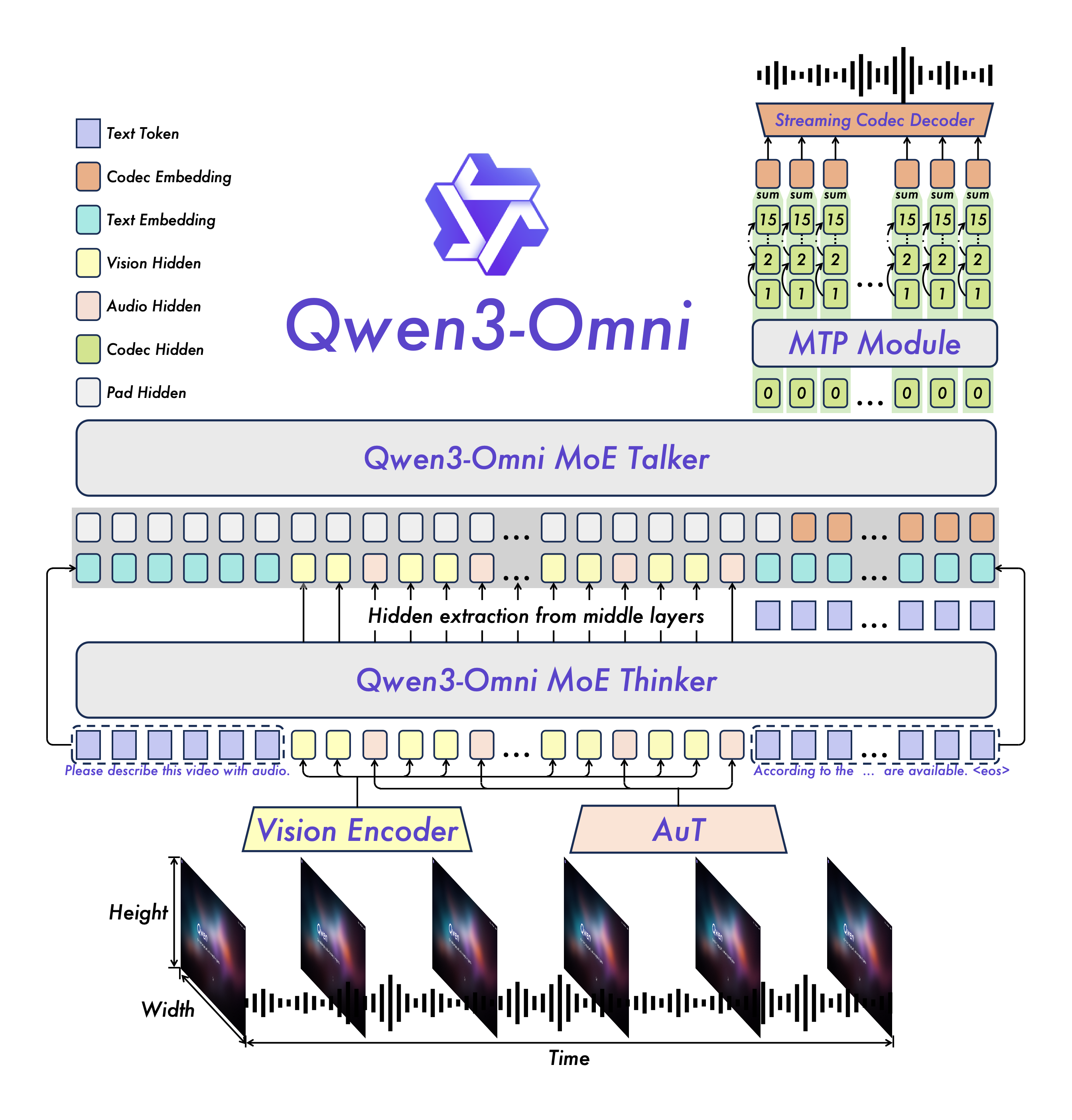
Qwen3-Omni unifies speech understanding, image understanding, video understanding and text generation with an end-to-end architecture, reducing the performance loss of traditional "speech pre-processing + LLM post-processing" and achieving low-latency voice dialogue and high-quality multimodal reasoning.
2. Balance between performance and latency
Qwen3-Omni has achieved advanced levels in multiple audio and video evaluations, while providing interactive latency and long-term audio comprehension capabilities of approximately 100 milliseconds, making it suitable for applications such as voice assistants, meeting minutes, real-time customer service, and content review.
(1) Indicator highlights
Qwen3-Omni takes the lead in more than 20 audio and audio-video benchmarks, with stable performance in voice dialogue, ASR, and multimodal understanding.
(2) Project highlights
End-to-end voice input to voice output reduces module splicing errors, system prompts are customizable, and built-in tool calls facilitate the expansion of business processes.
(3) Ecological highlights
Multiple models of Instruct, Thinking, and Captioner have been opened, compatible with mainstream reasoning frameworks, making it easy for developers to implement them.
2. How to implement Qwen3-Omni in business
1. List of typical scenarios and solutions
Voice Agent: Use Qwen3-Omni for real-time listening, speaking, reading, and writing, and integrate tool calls to connect to CRM and knowledge base.
Meetings and Interviews: Understand 30-minute audio clips and generate summaries, action lists, and searchable snippets.
Content production: Captioner provides low-illusion subtitles and descriptions to improve the efficiency of short video listing.
Education and Accessibility: Multilingual voice interaction and picture explanations to assist hearing-impaired and visually impaired users.
2. Deployment and cost points
For local inference, choose the 30B and A3B series for stronger general-purpose capabilities. Combine quantization and KV caching to optimize memory and throughput.
Cloud-based reasoning: Uses inference engines and streaming voice output to reduce end-to-end latency and ensure concurrency and stability.
(1) Quick Integration Checklist
a. Select a model: Instruct for instruction following, Thinking for complex reasoning, and Captioner for caption generation
b. Management prompts: Use system prompts to unify personality and tool calling specifications
c. Access tools: search, function call, work order system
d. Evaluation and regression: dual-track verification using multimodal benchmarks and business-specific integrated testing
3. Upgrade suggestions for AI teams
1. The evaluation system should be multimodal and closed-loop
Build an integrated evaluation set for text, images, audio, and video, covering ASR, speaker, spoken language understanding, video question answering, and fact consistency.
2. Data and security are equally important
Perform compliance filtering and redline detection on multimodal inputs; implement traceability and content watermarking strategies for speech and image generation results.
3. Evolving from “Assistant” to “Agent”
Relying on tool calls and system prompts, Qwen3-Omni is transformed into a multimodal AI agent with executable workflows, completing tasks in a closed loop from understanding the problem to calling the system and then to voice feedback.
4. Project Address:
https://github.com/QwenLM/Qwen3-Omni
https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct
Frequently Asked Questions (Q&A)
Q: What is the difference between Qwen3-Omni and traditional multimodal AI?
A: Qwen3-Omni emphasizes end-to-end and unified modeling, reducing the errors and delays caused by the series connection of multiple modules, while maintaining multimodal and text capabilities.
Q: How to choose between Qwen3-Omni-30B-A3B-Instruct and Thinking?
A: Instruct is suitable for production-level instruction following and tool calling, while Thinking focuses on complex reasoning and long-chain thinking. It is necessary to balance latency and reasoning depth according to the business.
Q: What is the purpose of Captioner's low illusion?
A: Captioner is suitable for video subtitles, product image descriptions, and accessibility scenarios. It can reduce the probability of "random talk based on pictures" and improve the efficiency of e-commerce and short video listings.
Q: How to connect Qwen3-Omni to voice customer service?
A: Use system prompts to define the script and compliance strategy, enable streaming voice input and output, and combine tool calls to connect to CRM, work orders, and knowledge base to form real-time Q&A and automatic recording.



