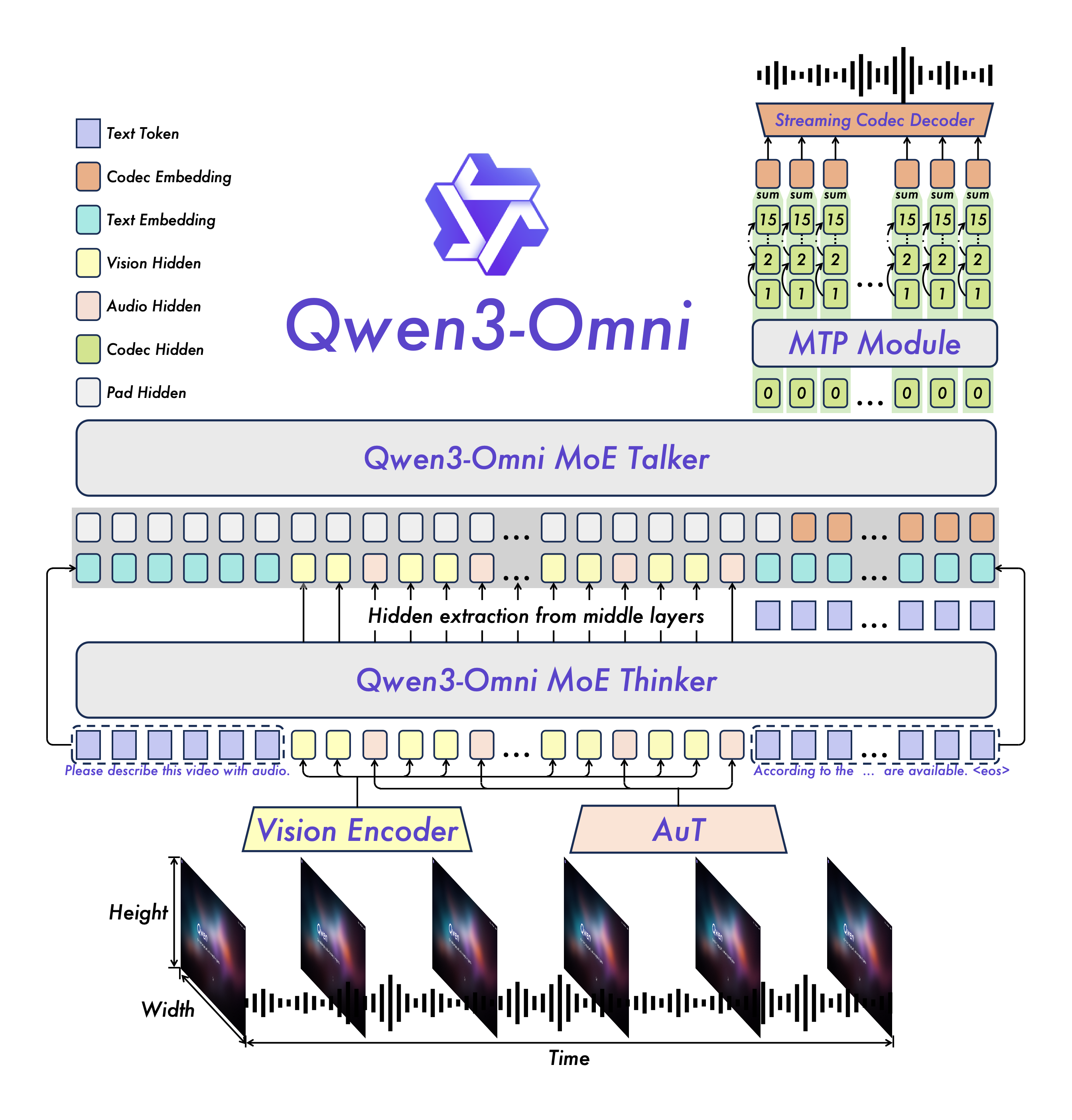
Qwen3-Omni kombiniert multimodale KI mit End-to-End-Reasoning: Ein einziges Modell vereinheitlicht die Eingabe und Ausgabe von Text, Bildern, Audio und Video und sorgt so für ein ausgewogenes Verhältnis zwischen Geschwindigkeit und Genauigkeit. In öffentlichen Tests erzielte Qwen3-Omni führende Ergebnisse bei einer Vielzahl von Audio- und Video-Benchmarks und bietet eine Vielzahl verfügbarer Gewichtungen, wodurch es sich für eine schnelle Einführung und Weiterentwicklung eignet.
1. Warum ist „durchgängige multimodale KI“ wichtig?
1. Wirklich einheitliche multimodale KI-Funktionen
Qwen3-Omni vereint Sprachverständnis, Bildverständnis, Videoverständnis und Textgenerierung mit einer End-to-End-Architektur, reduziert den Leistungsverlust der herkömmlichen „Sprachvorverarbeitung + LLM-Nachverarbeitung“ und erreicht Sprachdialoge mit geringer Latenz und hochwertiges multimodales Denken.
2. Balance zwischen Leistung und Latenz
Qwen3-Omni hat in mehreren Audio- und Videobewertungen fortgeschrittene Niveaus erreicht und bietet gleichzeitig interaktive Latenz- und langfristige Audioverständnisfunktionen von ungefähr 100 Millisekunden, wodurch es für Anwendungen wie Sprachassistenten, Besprechungsprotokolle, Echtzeit-Kundendienst und Inhaltsüberprüfung geeignet ist.
(1) Indikatoren-Highlights
Qwen3-Omni liegt bei mehr als 20 Audio- und Audio-Video-Benchmarks an der Spitze und bietet eine stabile Leistung bei Sprachdialogen, ASR und multimodalem Verständnis.
(2) Projekthighlights
Durchgängige Spracheingabe und Sprachausgabe reduzieren Fehler beim Modulspleißen, Systemaufforderungen sind anpassbar und integrierte Toolaufrufe erleichtern die Erweiterung von Geschäftsprozessen.
(3) Ökologische Highlights
Es wurden mehrere Modelle für Instruct, Thinking und Captioner geöffnet, die mit gängigen Denkrahmen kompatibel sind und Entwicklern die Implementierung erleichtern.
2. So implementieren Sie Qwen3-Omni im Unternehmen
1. Liste typischer Szenarien und Lösungen
Sprachagent: Verwenden Sie Qwen3-Omni zum Zuhören, Sprechen, Lesen und Schreiben in Echtzeit und integrieren Sie Tool-Aufrufe zur Verbindung mit CRM und Wissensdatenbank.
Besprechungen und Interviews: Verstehen Sie 30-minütige Audioclips und erstellen Sie Zusammenfassungen, Aktionslisten und durchsuchbare Ausschnitte.
Inhaltsproduktion: Captioner bietet Untertitel und Beschreibungen mit geringer Illusion, um die Effizienz der Auflistung kurzer Videos zu verbessern.
Bildung und Zugänglichkeit: Mehrsprachige Sprachinteraktion und Bilderklärungen zur Unterstützung hör- und sehbehinderter Benutzer.
2. Einsatz- und Kostenpunkte
Wählen Sie für lokale Inferenz die Serien 30B und A3B mit stärkeren Allzweckfunktionen. Kombinieren Sie Quantisierung und KV-Caching, um Grafikspeicher und Durchsatz zu optimieren.
Cloudbasiertes Schlussfolgern: Verwendet Inferenzmaschinen und Streaming-Sprachausgabe, um die End-to-End-Latenz zu reduzieren und Parallelität und Stabilität sicherzustellen.
(1) Checkliste für die schnelle Integration
a. Wählen Sie ein Modell: „Instruct“ für das Befolgen von Anweisungen, „Thinking“ für komplexe Schlussfolgerungen und „Captioner“ für die Untertitelgenerierung.
b. Management-Eingabeaufforderungen: Verwenden Sie Systemeingabeaufforderungen, um die Spezifikationen für Persönlichkeit und Tool-Aufrufe zu vereinheitlichen
c. Zugriffstools: Suche, Funktionsaufruf, Arbeitsauftragssystem
d. Evaluation und Regression: Dual-Track-Verifizierung mittels multimodaler Benchmarks und geschäftsspezifischer integrierter Tests
3. Upgrade-Vorschläge für KI-Teams
1. Das Bewertungssystem sollte multimodal und geschlossen sein
Erstellen Sie einen integrierten Bewertungssatz für Text, Bilder, Audio und Video, der ASR, Sprecher, Verständnis der gesprochenen Sprache, Beantwortung von Videofragen und Faktenkonsistenz abdeckt.
2. Daten und Sicherheit sind gleichermaßen wichtig
Führen Sie Compliance-Filterung und Redline-Erkennung für multimodale Eingaben durch; implementieren Sie Strategien zur Rückverfolgbarkeit und Inhaltswasserzeichen für Sprach- und Bildgenerierungsergebnisse.
3. Entwicklung vom „Assistenten“ zum „Agenten“
Qwen3-Omni basiert auf Tool-Aufrufen und Systemaufforderungen und verwandelt sich in einen multimodalen KI-Agenten mit ausführbaren Workflows, der Aufgaben in einem geschlossenen Kreislauf erledigt, vom Verständnis des Problems über den Aufruf des Systems bis hin zur Sprachrückmeldung.
4. Projektadresse:
https://github.com/QwenLM/Qwen3-Omni
https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct
Häufig gestellte Fragen (Q&A)
F: Was ist der Unterschied zwischen Qwen3-Omni und herkömmlicher multimodaler KI?
A: Qwen3-Omni legt Wert auf durchgängige und einheitliche Modellierung und reduziert die durch die Reihenschaltung mehrerer Module verursachten Fehler und Verzögerungen, während multimodale und Textfunktionen erhalten bleiben.
F: Wie wähle ich zwischen Qwen3-Omni-30B-A3B-Instruct und Thinking?
A: „Instruct“ eignet sich für die produktionsnahe Befolgung von Anweisungen und den Aufruf von Tools, während „Thinking“ sich auf komplexes Denken und Denken in langen Ketten konzentriert. Latenz und Argumentationstiefe müssen je nach Geschäftstätigkeit ausgeglichen werden.
F: Was ist der Zweck der niedrigen Illusion von Captioner?
A: Captioner eignet sich für Videountertitel, Produktbildbeschreibungen und Barrierefreiheitsszenarien. Es kann die Wahrscheinlichkeit von „zufälligem Sprechen basierend auf Bildern“ verringern und die Effizienz von E-Commerce und kurzen Videolisten verbessern.
F: Wie verbinde ich Qwen3-Omni mit dem Sprachkundendienst?
A: Verwenden Sie Systemaufforderungen, um das Skript und die Compliance-Strategie zu definieren, aktivieren Sie Streaming-Spracheingabe und -ausgabe und kombinieren Sie Tool-Aufrufe, um eine Verbindung zu CRM, Arbeitsaufträgen und Wissensdatenbanken herzustellen und so Fragen und Antworten in Echtzeit sowie eine automatische Aufzeichnung zu erstellen.



