Tongyi DeepResearch has officially been open-sourced. As a web agent for long-link retrieval and reasoning, it approaches OpenAI Deep Research on the same tasks. Officially, it achieved scores of 32.9 on Humanity's Last Exam, 45.3 on BrowseComp, and 75.0 on xbench-DeepSearch. The complete methodology and reproducible pipeline are available in open source, benefiting R&D, media, and e-commerce content teams. Tongyi DeepResearch emphasizes end-to-end reproducibility. By combining synthetic data, continuous pre-training, supervised fine-tuning, and reinforcement learning, along with search and tool-based strategies, the web agent achieves stable output on complex information collection and reasoning tasks, reducing the burden of secondary development for teams.
2. Performance Benchmarking and Indicator Interpretation
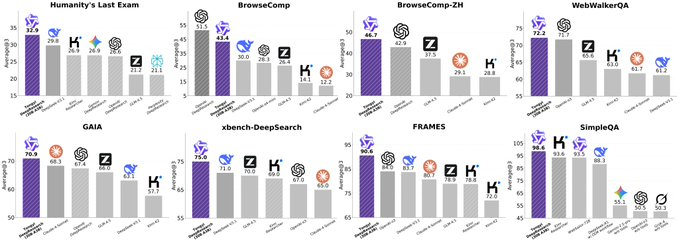
In the human final test, browsing retrieval, and user-oriented evaluation, Tongyi DeepResearch scored 32.9, 45.3, and 75.0, respectively, demonstrating its comparable performance in deep information search and evidence splicing, making it suitable for scenarios requiring long-term reasoning and multi-page cross-validation.
(1) Small Activation, Large Model
The design, with a total parameter count of 30B and activations of approximately 3B, balances reasoning capability and cost, and can be efficiently deployed on mainstream GPU clusters.
(2) Long-term Strategy and Tool Usage
Combining multi-step planning, evidence backtracking, and web tool calls, the Web Agent can form a closed loop from retrieval, comparison, to documentation.
(3) Adaptation of Chinese and industry themes
Maintaining stable performance in Chinese and English tasks and professional field questions and answers is conducive to cross-language content production and professional research.
II. Implementation path and team benefits
1. Typical implementation three-step method
The first step is to determine the business goals and evaluation set, the second step is to run the end-to-end process with the default configuration of Tongyi DeepResearch, and the third step is to connect to the own knowledge base and site whitelist to complete quality and compliance calibration.
2. Business scenario benefits
Media and research teams use it to sort out topics and align facts, e-commerce and brands use it for competitor research and multi-source evidence aggregation, and developers embed it into the workflow to generate structured reports with sources and reasoning chains.
(1) Quality control
Combine benchmark sets with manual sampling to track fact consistency, source diversity and traceability.
(2)Cost Control
Reduce long session costs through small activations and cache reuse, and dynamically allocate steps according to task complexity.
(3)Security and Compliance
Configure domain name whitelists, log retention, and sensitive word audits to ensure data minimization and traceability.
a. Team Collaboration
Build a system of prompt word templates and evidence library tags to reduce bias caused by personnel turnover.
b. Engineering Integration
Connect to existing pipelines with API gateways and queue rate limiting, supporting grayscale and rollback.
c. Iterative Evaluation
Continuously benchmark against BrowseComp and xbench-DeepSearch to observe the benefits of strategy and search updates.
Frequently Asked Questions (Q&A)
Q: What is the relationship between Tongyi DeepResearch and OpenAI Deep Research?
A: Tongyi DeepResearch is an open-source web agent that achieves comparable results on multiple benchmarks. Its goal is to replicate deep search and long-term reasoning capabilities in an open-source solution, making it easier for businesses and developers to implement.
Q: What is the significance of Tongyi DeepResearch's 30B total parameters and approximately 3B activations?
A: This design reduces inference costs while maintaining reasoning capabilities. It is suitable for production environments that require long-term link browsing and multi-evidence stitching, and is easier to deploy and schedule at scale.
Q: What do benchmark scores such as Humanity's Last Exam 32.9, BrowseComp 45.3, and xbench-DeepSearch 75.0 represent? A: The scores measure academic reasoning, real-world web retrieval, and user-directed deep search capabilities, respectively. Higher scores indicate greater reliability in complex information verification, browsing strategies, and evidence integration. Q: How does the team integrate Tongyi DeepResearch into existing content and R&D processes? A: A three-step approach: first, establish a business evaluation set and quality indicators, then run it through the default pipeline to access proprietary data and permission controls; finally, connect the output to the approval, release, and archiving systems, forming a closed loop.