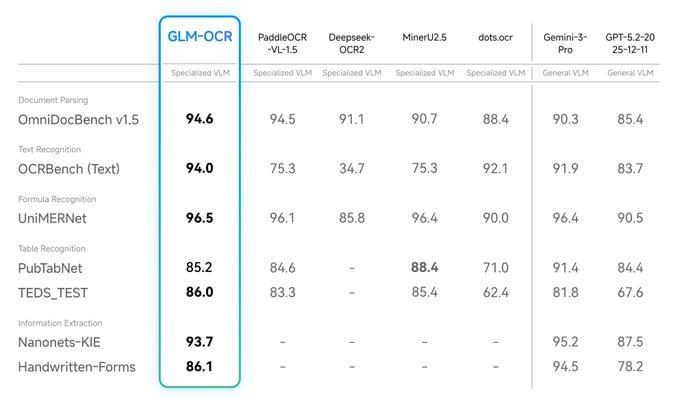
Z.ai released the multimodal OCR model GLM-OCR, which opens weights on Hugging Face, and provides online experience and API call methods. Officially, the model only has about 0.9B parameters, but it has achieved leading performance in complex document understanding tasks, covering scenarios such as formula recognition, table recognition, and key information extraction.
In terms of API usage, GLM-OCR supports the input of PDF and images (JPG/PNG), with a single image of no more than 10MB, PDF no more than 50MB, and a maximum of 100 pages. The output can include Markdown results and layout details for document parsing, data entry, and RAG document preprocessing. The actual effect will still be affected by scan quality, font mixing, seal occlusion and layout complexity, and it is recommended to conduct sampling evaluation and privacy compliance checks in the production environment.
FAQs
Q: What problems does GLM-OCR mainly solve?
A: GLM-OCR is suitable for OCR and understanding of complex documents, covering text, tables, formulas and information extraction.
Q: What inputs and size limits does GLM-OCR support?
A: GLM-OCR supports PDF and JPG/PNG, image ≤ 10MB, PDF ≤ 50MB, up to 100 pages.
Q: What are the forms of GLM-OCR output results?
A: GLM-OCR can output Markdown text results and return structured information related to layout.
Q: Does GLM-OCR provide an online experience and API?
A: Z.ai provides API interface descriptions on the online experience page and developer documentation.