1. Abstract
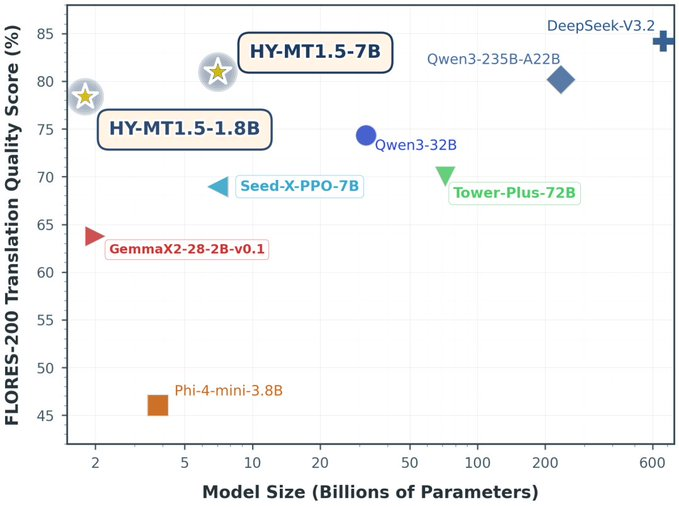
Tencent-HY-MT1.5 (HY-MT) is Tencent's open source machine translation model suite, which includes two scales: 1.8B (partial side/low resource) and 7B (partial cloud/high quality). The official emphasizes its collaborative deployment for "device-side + cloud-side": low latency and low memory usage on the device, stronger quality and more robust complex scene performance on the cloud, and covering 33+ languages/dialects (including some Min-Chinese and Chinese dialects) mutual translation capabilities.
2. Core features
1. Dual-model coverage of the end cloud: 1.8B adapts to consumer-grade hardware and offline/real-time translation; 7B is a higher quality version and is suitable for cloud batch and high-demand scenarios.
2. Speed and resource friendliness: 1.8B provides a quantized version, with an official caliber of about 1GB of memory usage and low-latency data of 50 tokens (depending on your hardware and inference framework).
3. Production enhancement capabilities: Natively support term intervention (custom term comparison), long conversation contextual translation, and formatted text translation (keep labels/typography as much as possible).
4. Multilingual coverage: In addition to common Chinese, English, Japanese, etc., it also covers a variety of minor languages; It is suitable for cross-border e-commerce, content internationalization and multilingual customer service.
3. Installation
- Environment preparation: It is recommended to give priority to using the officially recommended Transformers version (the repository example is a fixed version number) and prepare the GPU/CPU inference environment.
- Obtain the model: Download the corresponding weights (1.8B/7B, FP8, GPTQ Int4, etc.) from Hugging Face.
- Inference method: Construct a translation prompt template according to the model card/warehouse example (different translation templates for Chinese and foreign translations, foreign translation, and term/context/format translation templates are different), and then call the generation interface to output the translation.
4. Typical use cases
- Offline translation on the device side: low-latency scenarios such as mobile, desktop, browser plug-ins, and input method/stroke translation.
- High-quality translation in the cloud: batch translation of documents, international content production, and multilingual knowledge base construction.
- Consistency in industry terminology: Medical, legal, financial, software engineering documents, etc. require "no drift in terminology" text.
- Multi-round dialogue and customer service: Use historical dialogue as the context to reduce pronoun referencing errors and style breaks.
- Web page/tag text: HTML/tagged text translation, try to maintain the original structure to facilitate backfilling and rendering.
5. Ecology and competing products
- Ecosystem: Provide GitHub engineering examples and technical reports; Hugging Face offers a variety of precision/quantization versions to facilitate the choice of different inference costs on the device side and in the cloud.
- Competitive product reference: the open source side can be compared with MarianMT, NLLB series, M2M100, SeamlessM4T, etc.; The closed-source side is commonly used to translate the translation capabilities of various translation APIs or general-purpose large models. Actual selection recommendations are A/B tested based on your language coverage, format retention, terminology consistency, and throughput/latency metrics.
6. Limitations and precautions
- Indicator transferability: Official speed/memory data and effect rankings usually rely on specific hardware, quantification, and inference configurations, and need to be retested on the target device before launch.
- Prompt Dependence: Term/context/format translation needs to organize input strictly according to the template, otherwise there may be explanatory output or format shifts.
- Small languages and colloquial styles: Long-tail languages, slang, and strong field texts may still be mistranslated/omitted, so it is recommended to introduce a glossary and manual sampling to close the loop.
- Consistency between the device and the cloud: If the device side and the cloud side use different versions/quantization accuracy, the output style may not be completely consistent, and it needs to be converged through prompt words and terminology strategies.
7. Project address
https://github.com/Tencent-Hunyuan/HY-MT
8. Frequently asked questions
Q: What "end-side translation" scenarios is HY-MT1.5-1.8B suitable for?
A: It is suitable for applications that are sensitive to latency, have limited device resources, and require offline availability, such as mobile translation, IM embedded translation, browser stroke translation, etc.
Q: How to choose between HY-MT1.5-7B and 1.8B? Do you have to choose one or the other?
A: Device-side priority 1.8B, cloud priority 7B; You can also output results on the device side and review/re-translate in the cloud to obtain more stable quality and consistency.
Q: How does HY-MT1.5's "Termbase/Terminology Intervention" work?
A: According to the official terminology prompt template, the comparison of "source term → target term" is injected as a constraint, and then the body text is translated to improve the consistency of the terminology.
Q: How does HY-MT1.5 do long conversation context translation?
A: Use the historical dialogue as a context block input and use the context translation template to let the model refer to the context before translating the current sentence.
Q: What texts does HY-MT1.5 use for format-preserving translations?
A: Suitable for text that contains tags or tags (e.g., web page snippets/structured snippets). It is recommended to use small samples to verify that the labels are stable and retained, and then expand to the batch process.



