1. Zusammenfassung
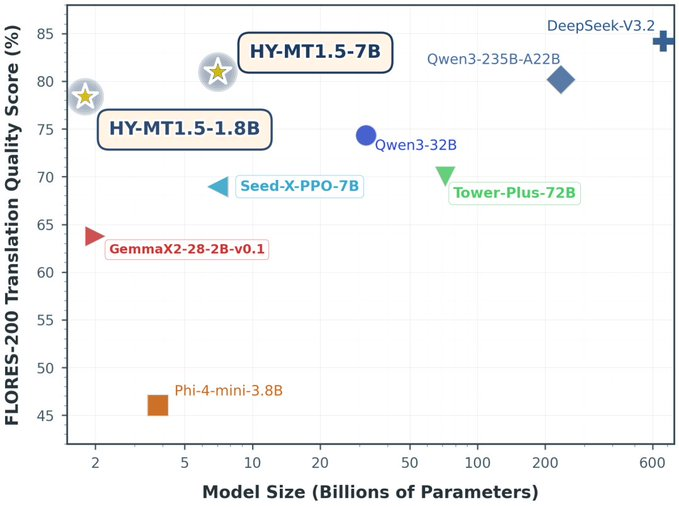
Tencent-HY-MT1.5 (HY-MT) ist Tencents Open-Source-Modellsuite für maschinelle Übersetzung, die zwei Skalierungen umfasst: 1,8B (teilweise Seite/wenig Ressourcen) und 7B (teilweise Cloud/hohe Qualität). Der Offizielle betont die kollaborative Implementierung für "Geräteseite + Cloud-Seite": niedrige Latenz und geringer Speicherverbrauch auf dem Gerät, höhere Qualität und robustere Leistung komplexer Szenen in der Cloud sowie die gegenseitige Übersetzungsmöglichkeiten von 33+ Sprachen/Dialekten (einschließlich einiger Min-chinesischer und chinesischer Dialekte).
2. Kernmerkmale
1. Dual-Modell-Abdeckung der Endcloud: 1,8B passt sich an Verbraucherhardware und Offline/Echtzeit-Übersetzung an; 7B ist eine hochwertigere Version und eignet sich für Cloud-Batch- und Hochbedarfsszenarien.
2. Geschwindigkeit und Ressourcenfreundlichkeit: 1.8B bietet eine quantisierte Version mit einem offiziellen Kaliber von etwa 1 GB Speicherverbrauch und latenzarmen Daten von 50 Token (abhängig von Hardware und Inferenz-Framework).
3. Produktionsverbesserungsfähigkeiten: Native Unterstützung von Begriffsinterventionen (benutzerdefinierter Begriffsvergleich), kontextuelle Übersetzung langer Gespräche und formatierte Textübersetzung (Etiketten/Typografie so weit wie möglich behalten).
4. Mehrsprachige Abdeckung: Neben dem allgemeinen Chinesisch, Englisch, Japanisch usw. umfasst es auch eine Vielzahl von Nebensprachen; Es eignet sich für grenzüberschreitenden E-Commerce, Internationalisierung von Inhalten und mehrsprachigen Kundenservice.
3. Installation
- Umgebungsvorbereitung: Es wird empfohlen, der offiziell empfohlenen Transformers-Version Vorrang zu geben (das Repository-Beispiel ist eine feste Versionsnummer) und die GPU/CPU-Inferenzumgebung vorzubereiten.
- Erhalte das Modell: Lade die entsprechenden Gewichte (1,8B/7B, FP8, GPTQ Int4 usw.) von Hugging Face herunter.
- Inferenzmethode: Erstellen Sie eine Übersetzungsvorlage entsprechend dem Beispiel der Modellkarte/Lagervorlagen (verschiedene Übersetzungsvorlagen für chinesische und ausländische Übersetzungen, ausländische Übersetzungen sowie Übersetzungsvorlagen für Begriffe/Kontext/Formate unterscheiden sich) und rufen Sie dann die Erzeugungsschnittstelle auf, um die Übersetzung auszugeben.
4. Typische Anwendungsfälle
- Offline-Übersetzung auf der Geräteseite: Szenarien mit niedriger Latenz wie Mobil-, Desktop-, Browser-Plug-ins und Eingabemethode/Strich-Übersetzung.
- Hochwertige Übersetzung in der Cloud: Batch-Übersetzung von Dokumenten, internationale Inhaltsproduktion und mehrsprachige Wissensdatenbank.
- Konsistenz in der Branchenterminologie: Medizinische, rechtliche, finanzielle, softwaretechnische Dokumente usw. erfordern einen Text ohne Terminologieabweichungen.
- Mehrrunden-Dialog und Kundenservice: Nutze historischen Dialog als Kontext, um Pronomen-Referenzfehler und Stilbrüche zu reduzieren.
- Webseiten-/Tag-Text: HTML-/getaggte Textübersetzung, versuchen Sie, die Originalstruktur beizubehalten, um Backfill und Rendering zu erleichtern.
5. Ökologie und konkurrierende Produkte
- Ökosystem: Bereitstellung von GitHub-Engineering-Beispielen und technischen Berichten; Hugging Face bietet eine Vielzahl von Präzisions- und Quantisierungsversionen an, um die Wahl verschiedener Inferenzkosten sowohl auf der Geräteseite als auch in der Cloud zu erleichtern.
- Konkurrenzproduktreferenz: Die Open-Source-Seite kann mit MarianMT, NLLB-Serie, M2M100, SeamlessM4T usw. verglichen werden; Die Closed-Source-Seite wird häufig verwendet, um die Übersetzungsfähigkeiten verschiedener Übersetzungs-APIs oder allgemeiner großer Modelle zu übersetzen. Die tatsächlichen Auswahlempfehlungen werden auf Basis deiner Sprachabdeckung, Formatbehalt, Terminologiekonsistenz und Durchsatz-/Latenzmetriken A/B getestet.
6. Einschränkungen und Vorsichtsmaßnahmen
- Indikatorübertragbarkeit: Offizielle Geschwindigkeits-/Speicherdaten und Effektbewertungen basieren in der Regel auf spezifischer Hardware-, Quantifizierungs- und Inferenzkonfigurationen und müssen vor dem Start am Zielgerät erneut getestet werden.
- Promptabhängigkeit: Die Übersetzung von Begriffen, Kontexten und Formaten muss die Eingabe streng nach Vorlage organisieren, andernfalls kann es zu erklärenden Ausgaben oder Formatänderungen kommen.
- Kleine Sprachen und umgangssprachliche Stile: Langschwanzsprachen, Slang und starke Feldtexte können weiterhin falsch übersetzt oder weggelassen werden, daher wird empfohlen, ein Glossar und eine manuelle Stichprobe einzuführen, um die Schleife zu schließen.
- Konsistenz zwischen Gerät und Cloud: Wenn die Geräteseite und die Cloud-Seite unterschiedliche Versionen bzw. Quantisierungsgenauigkeit verwenden, ist der Ausgabestil möglicherweise nicht vollständig konsistent und muss durch Promptwörter und Terminologiestrategien konvergiert werden.
7. Projektadresse
https://github.com/Tencent-Hunyuan/HY-MT
8. Häufig gestellte Fragen
F: Für welche "End-Side-Translation"-Szenarien eignet sich HY-MT1.5-1.8B?
A: Es eignet sich für Anwendungen, die empfindlich auf Latenz reagieren, begrenzte Geräteressourcen haben und eine Offline-Verfügbarkeit erfordern, wie mobile Übersetzung, IM-Embedded-Übersetzung, Browser-Schlagübersetzung usw.
F: Wie wählt man zwischen HY-MT1.5-7B und 1.8B? Muss man sich für das eine oder das andere entscheiden?
A: Geräte-seitige Priorität 1,8B, Cloud-Priorität 7B; Du kannst auch Ergebnisse auf der Geräteseite ausgeben und in der Cloud überprüfen/neu übersetzen, um eine stabilere Qualität und Konsistenz zu erreichen.
F: Wie funktioniert die "Termbase/Terminology Intervention" von HY-MT1.5?
A: Laut der offiziellen Terminologie-Promptvorlage wird der Vergleich von "Quellbegriff → Zielbegriff" als Einschränkung eingefügt und anschließend der Haupttext übersetzt, um die Konsistenz der Terminologie zu verbessern.
F: Wie übersetzt HY-MT1.5 den Kontext für lange Gespräche?
A: Verwenden Sie den historischen Dialog als Kontextblock-Eingabe und verwenden Sie die Kontextübersetzungsvorlage, damit das Modell vor der Übersetzung des aktuellen Satzes auf den Kontext verweisen kann.
F: Welche Texte verwendet HY-MT1.5 für formatbewahrende Übersetzungen?
A: Geeignet für Texte, die Tags oder Tags enthalten (z. B. Webseitenausschnitte/strukturierte Ausschnitte). Es wird empfohlen, kleine Proben zu verwenden, um zu überprüfen, ob die Etiketten stabil und erhalten sind, und dann auf den Batch-Prozess auszuweiten.



