1. Zusammenfassung
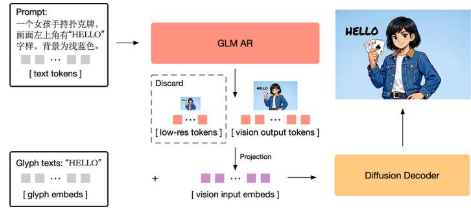
GLM-Image ist ein Open-Source-Bildgenerierungsmodell von Z.ai, das ein hybrides Paradigma aus "diskreter autoregressiver Generierung + Diffusionsdekodierung" verwendet: Das autoregressive Modul ist für globale Semantik und Layoutplanung verantwortlich, und der Diffusionsdecoder wird mit hochauflösenden Details ergänzt. Offizielle Informationen weisen darauf hin, dass die Gesamtbildqualität mit dem Mainstream-Diffusionsweg übereinstimmen kann und gleichzeitig bei Textrendering und wissensintensiven Bildern (Poster, PPTs, populärwissenschaftliche Diagramme) besonders hervorzutreten.
2. Kernmerkmale
- Hybride Architektur: Berücksichtigen Sie das Instruktionsverständnis (global) und die Detailwiederherstellung (lokal).
- Stabilerer Text: besser geeignet für mehrzeiligen Text, Überschriften/Unterüberschriften-Hierarchie und Informationskartenlayout.
- Wissensintensive Generierung: Bilder für "Informationsausdruck zuerst", wie Flussdiagrammplakate und Annotationsdiagramme.
- Wensheng-Diagramm + Tushengtu: Unterstützung bei der Generierung, Bearbeitung und Aufgaben im Zusammenhang mit Stil/Konsistenz (vorbehaltlich offizieller Beispiele).
3. Installation
- Code und Gewicht abrufen: GitHub-Klon-Repository; Laden Sie die Modellgewichte von Hugging Face herunter.
- Python-Inferenz: Installieren Sie Abhängigkeiten wie Transformatoren/Diffusoren gemäß den Repository-Anweisungen und laden Sie die Pipeline zur Erzeugung.
- Schnittstellenaufruf: Sie können direkt den Image/Generations-Endpunkt der Z.ai API verwenden, um Parameter wie Prompt und Größe einzugeben.
4. Typische Anwendungsfälle
- Plakate und Veranstaltungsmaterialien: Werbegrafiken mit "klarem und lesbarem Text + stabilem Layout" sind erforderlich.
- PPT Informationsseite: Kapitelcover, Hauptpunkte, Vergleichstabellen und andere informationsreiche Bildschirme.
- Populärwissenschaftliches Diagramm und Annotationsdiagramm: Betonen Sie semantische Korrektheit und Informationsstruktur statt reiner stilisierter Kunst.
- Markenkonsistenz-Ausgabe: Mehrere Bilder halten den Stil mit dem Hauptteil konsistent und reduzieren Überarbeitungen.
5. Ökologie und konkurrierende Produkte
- Ökologie: Hugging Face bietet Modelle und Anleitungen; Offizielle Dokumentation stellt APIs und Parameter bereit; GitHub bietet native Schlussfolgerungen und Beispiele.
- Konkurrenzprodukte: Im Vergleich zu gängigen Routen wie SDXL/SD3 und FLUX ist GLM-Image eher zum "Text + Wissensausdruck"-Szenario geneigt; Universelle Stilabdeckung und Kostenempfehlungen nutzen Sie Ihre Prompts, um die Daten zu vergleichen und zu bewerten.
6. Einschränkungen und Vorsichtsmaßnahmen
- Rechenleistungsgrenze: Hybridarchitektur und hochauflösende Generierung erfordern möglicherweise mehr Videospeicher und Unterstützung für mehrere Karten.
- Maßbedingungen: Es ist üblich, dass Breite und Höhe ein bestimmtes Vielfaches (z. B. ein Vielfaches von 32) sind, andernfalls kann ein Fehler gemeldet werden.
- Text muss weiterhin akzeptiert werden: Manuelle Überprüfung wird für kleine Schriftgrößen, komplexe Schriftarten und mehrsprachige, gemischte Layout-Szenarien empfohlen.
7. Projektadresse
https://github.com/zai-org/GLM-Image
8. Häufig gestellte Fragen
F: Was sind die Vorteile der hybriden Architektur "Autoegression + Diffusion Decoding" von GLM-Image?
A: Selbstregression ist besser in globaler Semantik und Layoutplanung, Diffusion besser bei der Detail- und Texturvollständigkeit und fördert eher die informationsdichte Bilderzeugung nach der Kombination.
F: Warum ist GLM-Image vorteilhafter bei der Darstellung von Bildern auf Chinesisch?
A: Die offiziellen Unterlagen betonen, dass es speziell für Text- und Informationsausdruck entworfen und geschult wurde, wodurch der generierte Text klarer und näher am erwarteten Layout liegt.
F: Für welche wissensintensiven Szenarien eignet sich GLM-Image?
A: Plakate, PPT-Informationsseiten, populärwissenschaftliche Diagramme, Bilder mit multiregionaler Annotation und hierarchischen Informationen.
F: Kann GLM-Image Bildgenerierung und -bearbeitung übernehmen?
A: Ja, die Repository- und Modellseiten liefern relevante Nutzungs- und Beispielparameter (vorbehaltlich des offiziellen).
F: Was soll ich tun, wenn GLM-Image lokal nicht laufen kann?
A: Reduzieren Sie zuerst die Auflösung und Anzahl der Schritte, verwenden Sie bei Bedarf größeren Speicher/mehrere Karten oder verwenden Sie stattdessen die Z.ai API.
F: Warum verursacht die Größenfehler bei der erzeugten GLM-Image?
A: Der häufige Grund ist, dass Breite und Höhe die vom Modell geforderten Mehrfachbedingungen nicht erfüllen; Passen Sie die konformen Maße gemäß dem Dokument an.