一、摘要
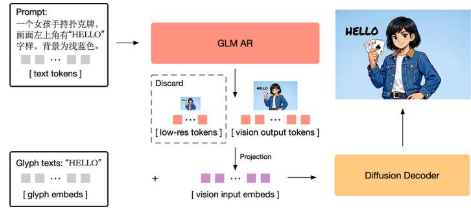
GLM-Image 是 Z.ai 开源的图像生成模型,采用“离散自回归生成 + 扩散解码”的混合范式:自回归模块负责全局语义与布局规划,扩散解码器补足高保真细节。官方资料指出,它整体画质可对齐主流扩散路线,同时在文字渲染与知识密集型图像(海报、PPT、科普示意图)表现更突出。
二、核心特性
1、混合架构:兼顾指令理解(全局)与细节还原(局部)。
2、文字更稳:更适合多行文本、标题/副标题层级与信息卡片式排版。
3、知识密集生成:面向“信息表达优先”的图片,如流程图式海报、标注示意图。
4、文生图 + 图生图:支持生成、编辑与风格/一致性相关任务(以官方示例为准)。
三、安装
1、获取代码与权重:GitHub 克隆仓库;从 Hugging Face 下载模型权重。
2、Python 推理:按仓库说明安装 Transformers/Diffusers 等依赖,加载管线进行生成。
3、接口调用:可直接使用 Z.ai API 的 images/generations 端点,传入 prompt 与尺寸等参数。
四、典型用例
1、海报与活动物料:需要“清晰可读文字 + 稳定布局”的宣传图。
2、PPT 信息页:章节封面、要点卡片、对比图等信息密集画面。
3、科普示意与标注图:强调语义正确与信息结构,而非纯风格化美术。
4、品牌一致性输出:多张图保持风格与主体一致,减少返工。
五、生态与竞品
1、生态:Hugging Face 提供模型与说明;官方文档提供 API 与参数;GitHub 提供本地推理与示例。
2、竞品:与 SDXL/SD3、FLUX 等主流路线相比,GLM-Image 更偏“文字+知识表达”场景;通用风格覆盖与成本建议用你的提示词与数据做对比评测。
六、局限与注意事项
1、算力门槛:混合架构与高分辨率生成可能需要较高显存/多卡支持。
2、尺寸约束:常见要求宽高为特定倍数(如 32 的倍数),否则可能报错。
3、文字仍需验收:小字号、复杂字体、多语言混排场景建议人工复核。
七、项目地址
https://github.com/zai-org/GLM-Image
八、常见问题
Q: GLM-Image 的“自回归+扩散解码”混合架构带来什么收益?
A: 自回归更擅长全局语义与布局规划,扩散更擅长细节与纹理补全,组合后更利于信息密集图片生成。
Q: 为什么 GLM-Image 在图片中文字渲染上更有优势?
A: 官方资料强调其面向文字与信息表达做了专门设计与训练,使生成文字更清晰、更接近预期排版。
Q: GLM-Image 适合哪些知识密集型场景?
A: 海报、PPT 信息页、科普示意图、带多区域标注与层级信息的图片。
Q: GLM-Image 能否做图生图/编辑?
A: 支持,仓库与模型页提供相关用法与示例参数(以官方为准)。
Q: GLM-Image 本地跑不动怎么办?
A: 先降低分辨率与步数,必要时使用更大显存/多卡,或改用 Z.ai API。
Q: GLM-Image 生成尺寸为什么会报错?
A: 常见原因是宽高不满足模型要求的倍数约束;按文档调整为合规尺寸即可。