一、性能结论
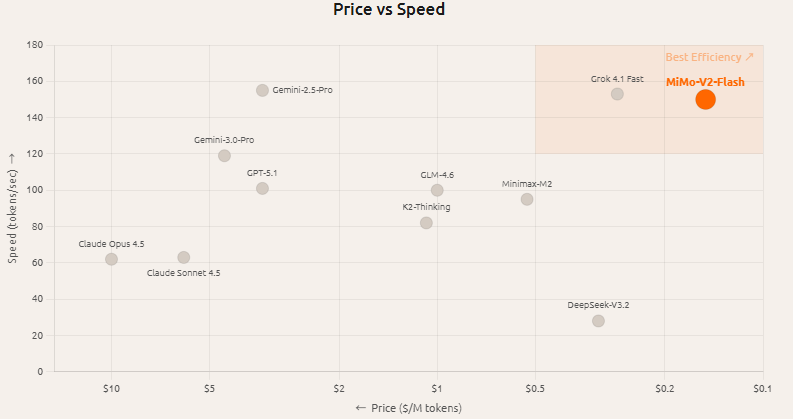
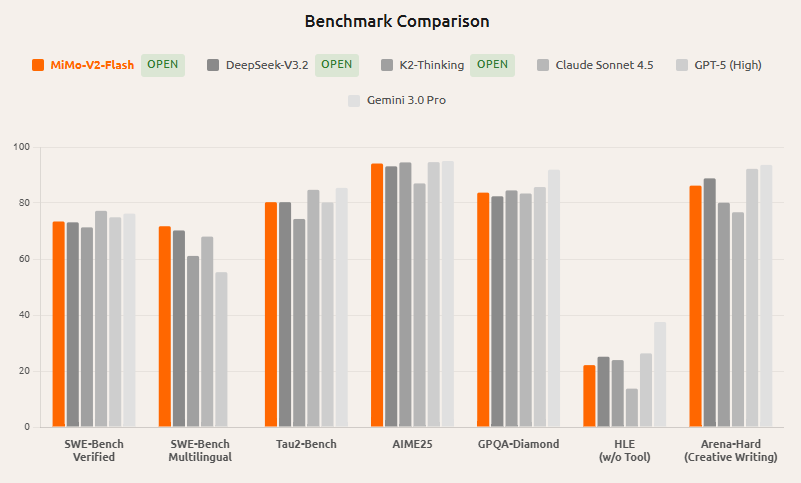
小米 MiMo 系列中,MiMo-V2-Flash 走“高效能密度”路线:MoE 架构 309B 总参数、约 15B 激活参数。其模型卡显示在多项通用与推理基准上表现强势,代码与 Agent 相关评测尤为突出。
二、速度与成本
官方介绍其采用混合注意力、多词元预测等设计以降低推理开销,并提供 256k 长上下文,更偏向多轮工具调用与工作流场景。
三、对标怎么看
不少第三方解读将其与 DeepSeek-V3.2 等高阶开源模型放在同档对比;但不同榜单题库、是否用工具、推理设置差异很大,分数不宜直接等同,建议看同条件复现结果。
四、落地建议
判断是否“适合你”,用自家任务集做离线 A/B:关注吞吐与时延、幻觉率、工具成功率与单位成本;本地部署再评估量化、并行与框架适配度。
五、Q&A 常见延伸问题
Q:309B 是不是很难跑?
A:推理主要激活约 15B,但仍建议较强 GPU/多卡;量化可显著降低门槛。
Q:更适合写代码还是聊天?
A:定位更偏推理、编码与 Agent 工作流;纯聊天风格与稳定性要以你场景实测为准。
Q:还有更小的 MiMo 吗?
A:有,MiMo 也发布过 7B 推理导向模型,适合轻量研究与对比。