一、基本信息
悟界·Emu3.5 多模态世界模型由北京智源人工智能研究院团队推出,是一款面向视觉与语言统一建模的原生多模态世界模型。围绕悟界·Emu3.5,官方同步提供了 Web 体验平台和相关客户端,方便科研用户、企业开发者及内容创作者直接使用模型能力。
悟界·Emu3.5 被定位为多模态世界模型基座,通过开源模型与在线体验结合的方式,兼顾科研可复现性与产品级易用性,为多模态内容生成和世界建模相关应用提供基础支撑。
二、产品概述
悟界·Emu3.5 的核心目标是实现统一的世界建模能力,在同一模型中同时处理图像与文本,将二者视作统一序列进行建模与生成。用户既可以输入纯文本,也可以输入图文混合内容,让模型输出图像、文字或图文交错内容。
面向普通用户,悟界·Emu3.5 提供 Web 体验页面,集成创作工作区、案例展示和历史记录管理等功能,可快速完成文本生成图像、图像编辑和图文创作。面向技术和科研用户,可通过开源仓库在本地或服务器部署模型,用于实验和二次开发。
三、核心功能
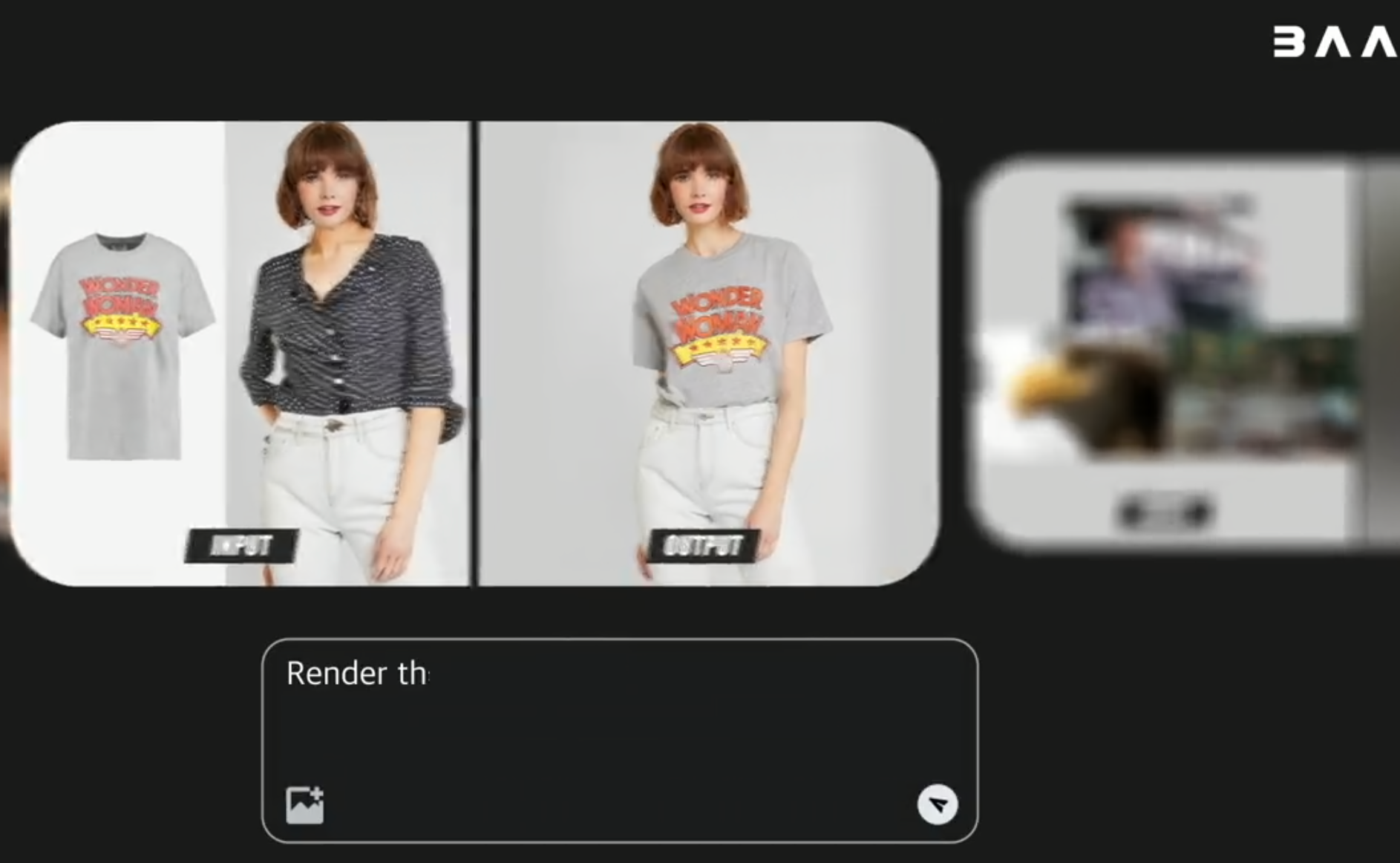
1、主要功能
- 文本生成图像
- 支持根据自然语言描述生成高质量图像,适用于插画、配图、海报草图等创作场景。
- 任意到图像生成
- 支持以图生图和图文联合引导生成,在保留主体结构的前提下进行风格迁移、元素替换和布局调整。
- 图像编辑与修复
- 可对图像局部进行擦除、替换和增强,用于细节修改、物体添加、背景调整等图像编辑任务。
- 图文交错内容生成
- 生成由多张图像和相应文字说明组成的内容序列,适合视觉故事、教程说明与多步骤演示。
2、技术特性
悟界·Emu3.5 采用统一的序列建模方式,将视觉标记与文本标记统一处理,形成端到端的原生多模态框架。模型在大规模多模态数据上训练,重点利用长视频及其文本描述,以学习时空连续性和世界动态结构。
在推理阶段,模型提供针对图像生成任务的加速方案,兼顾生成质量与效率,适合在科研环境和产品原型中落地使用。
四、适用场景与人群
悟界·Emu3.5 多模态世界模型适用于以下人群和场景:
- 科研与教学:高校和研究机构用于多模态学习、世界建模、视频理解与生成等方向研究及课程实验。
- 内容创作与设计:插画师、设计师、新媒体团队用于快速生成创意草图、氛围图和配图素材,提高内容产出效率。
- 开发与产品创新:企业技术团队将悟界·Emu3.5 作为底层模型,构建多模态助手、视觉生成工具或具备图文理解能力的智能体应用。
五、常见问题
Q: 悟界·Emu3.5 多模态世界模型的核心定位是什么?
A: 悟界·Emu3.5 的核心定位是统一建模视觉与语言的多模态世界模型基座,通过开源模型与在线平台结合,为科研实验与应用开发提供统一的多模态能力。
Q: 悟界·Emu3.5 Web 平台主要适合哪些用户使用?
A: 悟界·Emu3.5 Web 平台主要面向内容创作者、设计师、新媒体团队以及对多模态创作有需求的普通用户,用于文本生成图像、图像编辑和图文内容创作等任务。
Q: 悟界·Emu3.5 是否支持本地部署和二次开发?
A: 悟界·Emu3.5 提供开源代码和模型权重,支持在本地或服务器环境部署,开发者可以在遵守相关开源许可证条款的前提下进行研究、测试和二次开发。



