I. 요약
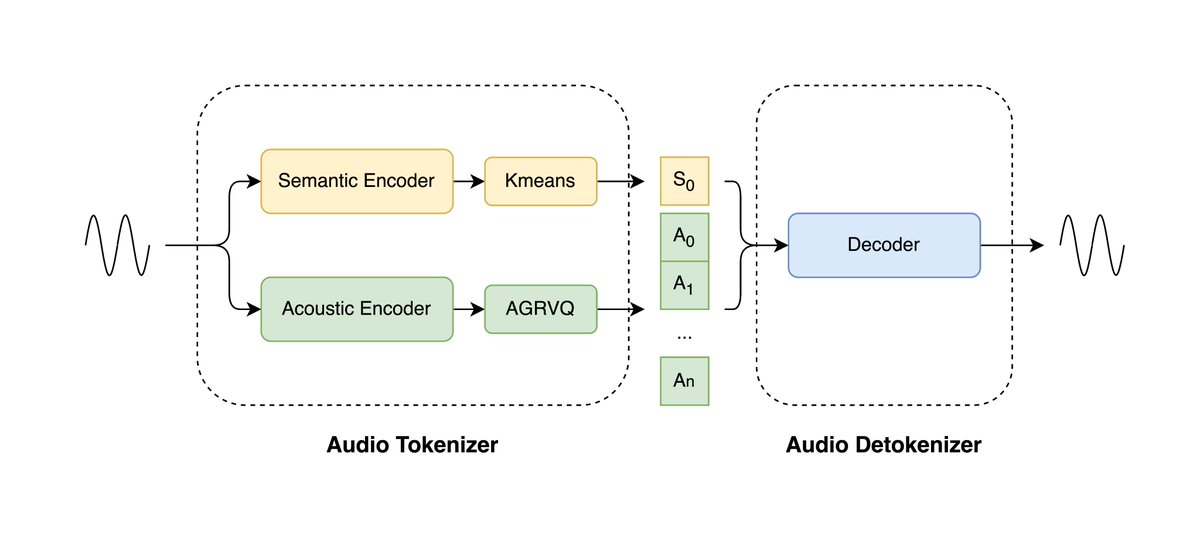
LongCat-Audio-Codec은 Meituan LongCat 팀이 개발한 오픈소스 오디오 코덱 솔루션으로, 음성 대규모 모델(LLM)에 최적화되어 있습니다. 이 프로젝트는 듀얼 토큰 아키텍처를 활용하여 의미 정보와 음향 정보를 동시에 모델링하여 0.43kbps의 초저 비트레이트에서도 음성 명료도와 품질을 유지합니다. 실시간 스트리밍 디코더는 수백 밀리초 단위의 지연 시간을 유지하여 음성 상호작용 및 임베디드 배포를 지원합니다. 디코더에 통합된 초고해상도 모듈은 추가 모델 없이도 음질을 더욱 향상시켜 엔드투엔드 음성 시스템의 리소스 오버헤드를 크게 줄입니다.
2. 핵심 기능
1. 듀얼 토큰 병렬 인코딩 : 의미 토큰과 음향 토큰을 동시에 추출하여 16.7Hz(60ms)의 낮은 프레임 속도에서 효율적인 기능 모델링을 달성합니다.
2. 매우 낮은 비트레이트와 고충실도 재구성 : 0.43kbps의 높은 명료도를 유지하여 대역폭 활용도를 크게 향상시킵니다.
3. 실시간 저지연 디코딩 : 스트리밍 아키텍처를 사용하여 전체 지연 시간을 수백 밀리초로 유지하여 실시간 음성 생성 및 상호 작용의 요구 사항을 충족합니다.
4. 디코딩 측 초고해상도 향상 : 통합 초고해상도 모듈은 외부 모델이 필요 없이 사운드 품질 세부 사항을 개선합니다.
5. 가볍고 모바일에 최적화된 아키텍처 : 임베디드 및 모바일 기기의 컴퓨팅 성능 한계를 해결하기 위한 아키텍처 최적화.
3. 설치
1. 저장소 복제: git clone https://github.com/meituan-longcat/LongCat-Audio-Codec
2. 설치 종속성: pip install -r requirements.txt
3. 모델 로드: Hugging Face를 통해 meituan-longcat/LongCat-Audio-Codec의 해당 가중치를 다운로드할 수 있습니다.
- 예제 실행: 저장소에서 추론 스크립트를 실행하여 인코딩 및 디코딩 검증을 수행합니다.
일반적인 사용 사례
- 대규모 음성 모델의 프런트엔드 압축: 이해도를 유지하면서 입력 대역폭을 줄입니다.
- 실시간 음성 상호작용 시스템: 대화형 AI 또는 음성 비서에서 저지연 전송을 실현합니다.
- 엣지 및 모바일 기기에서의 음성 합성: 로컬에서 음성을 생성하거나 디코딩합니다.
- 장거리 음성 통신: 대역폭이 매우 낮은 환경에서도 선명한 음성 전송 품질을 유지합니다.
5. 생태계 및 경쟁 제품
1. 생태계 통합 : LongCat-Audio-Codec은 Meituan LongCat 시리즈 생태계의 일부이며 LongCat-Flash와 같은 모델과 협력하여 음성 생성 및 이해를 최적화합니다.
2. 경쟁사와의 비교 : SemantiCodec, UniCodec, LMCodec 등의 신경망 코덱 솔루션과 비교했을 때, LongCat-Audio-Codec은 음성 분야에서 더 낮은 비트 전송률과 더 강력한 실시간 성능을 달성합니다.
3. 산업적 중요성 : 음성 LLM의 배포 임계값을 낮추고 모바일 AI 어시스턴트 및 음성 서비스에 대한 인프라 지원을 제공합니다.
VI. 제한 사항 및 주의사항
- 비트 전송률이 매우 낮더라도 세부 정보가 손실되어 사운드 품질이 저하될 수 있습니다.
- 스트리밍 디코딩에는 하드웨어 실시간 성능에 대한 높은 요구 사항이 있습니다.
- 모델 버전에 따라 지연 시간과 음질 사이에 균형이 필요할 수 있습니다.
- 초고해상도 모듈을 통합하면 계산 부담이 증가합니다.
7. 프로젝트 주소
https://github.com/meituan-longcat/롱캣-오디오-코덱
8. 자주 묻는 질문
질문: LongCat-Audio-Codec은 오프라인 배포를 지원합니까?
A: 완전히 오프라인으로 실행할 수는 있지만, 해당 모델 가중치와 종속 환경을 준비해야 합니다.
질문: 이 코덱을 모바일 기기에 통합하려면 어떻게 해야 하나요?
A: 양자화된 모델이나 가벼운 추론 프레임워크를 통해 모바일이나 임베디드 플랫폼으로 이식할 수 있습니다.
질문: 음성이 아닌 오디오에도 사용할 수 있나요?
A: 현재 버전은 주로 음성 작업에 최적화되어 있으며, 다른 유형의 오디오에는 추가 교육이 필요합니다.



