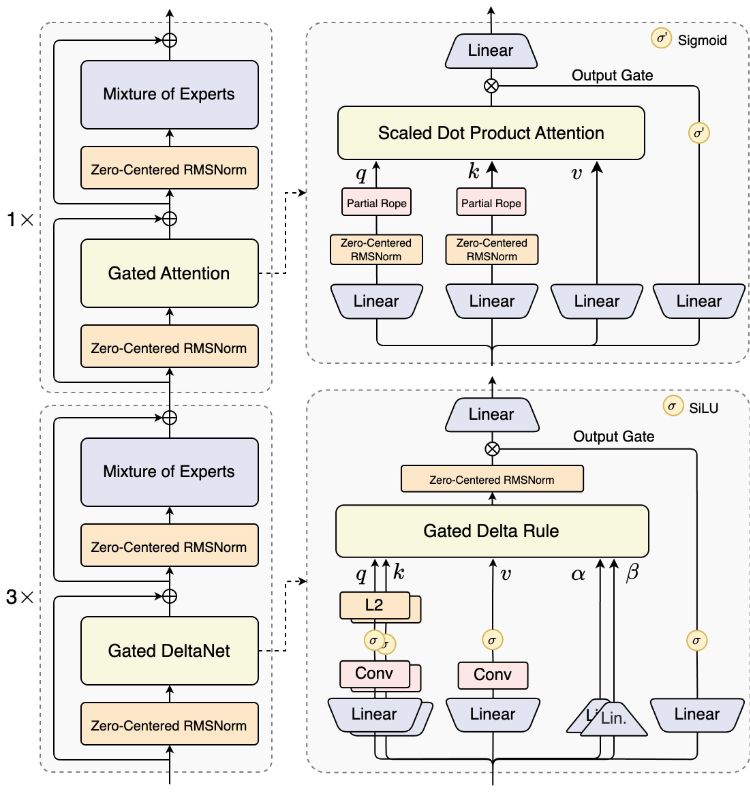
Qwen3-Next-80B-A3B는 총 매개변수 80B에 중점을 두고 토큰당 3B 활성화만 가능하며 하이브리드 아키텍처(Gated DeltaNet+Gated Attention), 초희소 MoE(전문가 512명, 경로 10개 + 공유 1개) 및 다중 토큰 예측을 채택합니다. 생각 버전.
1. 빠른 요약
1. 핵심 매개변수 및 포지셔닝
Qwen3-Next-80B-A3B는 큰 모델 용량을 80B 매개변수와 일치시키지만 3B 활성화를 통해 매우 희박한 MoE를 달성합니다. 32K 이상의 긴 컨텍스트의 경우 높은 처리량과 낮은 대기 시간을 강조하므로 검색 향상 및 다중 문서 워크플로에 적합합니다.
2. 아키텍처 하이라이트
하이브리드 솔루션은 Gated DeltaNet 및 Gated Attention을 도입하고 라우팅 게이팅을 가진 512명의 전문가 중 10+1을 선택합니다. MTP 다중 토큰 예측 및 투기 디코딩 연계를 통해 생성 효율성과 안정성을 향상시킵니다. A3B 경로는 "대규모 일반 직원과 소규모 활성화"의 비용 효율성을 보장합니다.
3. 성능 벤치마킹
공식 구경은 훈련 비용이 Qwen3-32B보다 약 한 배 낮고 32K+ 장면의 추론 처리량이 크게 향상되었다고 말했습니다. Instruct는 235B 플래그십에 가깝고 Thinking 버전은 추론 및 긴 맥락에서 주류 사고 사슬 모델을 벤치마킹합니다.
2. 구현 및 사용
1. 고부가가치 시나리오
(1) 긴 문서 RAG 및 검색 Q&A: 긴 컨텍스트와 높은 처리량을 사용하여 대규모 지식 블록 처리
(2) 다라운드 비즈니스 도우미: 교차 파일 명령, 테이블 및 코드 혼합 작업
(3) 일괄 처리 및 오프라인 생성: MTP 희소 경로로 처리량 및 비용 최적화
2. 배포 및 튜닝 제안
(1) KV-Cache 계층화 및 병렬 일괄 처리, 32K/64K 기어 최적화에 우선 순위 부여
(2) 대역폭 핫스팟을 줄이기 위한 전문가 라우팅에 따른 병렬 텐서 분할
(3) 프롬프트 단어 추적: 검색, 코드 및 사고 사슬 템플릿은 별도로 유지 관리됩니다
3. 마이그레이션 및 평가 체크리스트
(1) Qwen3-32B/Qwen3-235B 기준선을 설정하고 평가 스크립트를 통합
합니다.(2) 품질, 처리량 및 비용을 각각 3차원으로 측정합니다. 컨텍스트 길이가 성능에 미치는 영향 기록
(3) 그레이스케일 교체: 먼저 긴 컨텍스트에서 동시성이 높은 시나리오 간에 전환한 다음 점차적으로 일반 대화 3
. 위험 통제 및 규정 준수
1. 비용 및 할당량
(1) 임차인 및 프로젝트에 따라 통화 할당량 및 예산 경보 설정
(2) 대규모 배치 작업을 오프라인 일괄 처리로 변경하여 최대 오버헤드를 줄입니다
(3) 암묵적 낭비를 방지하기 위해 요청당 토큰/KV의 적중률을 모니터링
합니다.2. 관찰 가능성 및 품질 회귀
(1) 사고 사슬 및 인용 증거 요약 보존 시행
(2) 주요 채널에 대한 수동 샘플링 및 롤백 활성화
(3) 버전 잠금: 모델, 3
. 라이선스 및 데이터 보안
(1) 모델 가중치 및 API 라이선스 조건 준수
(2) 최소 권한으로 엔터프라이즈 데이터에 액세스하고 감사 로그 활성화
(3) 출력된 민감한 콘텐츠자주 묻는 질문(Q&A)
Q: Qwen3-Next-80B-A3B의 A3B 및 초희소 MoE의 장점은 무엇입니까?
A: A3B를 사용하면 3B 활성화만으로 80B 일반 직원이 전달에 참여할 수 있으며, 512명의 전문가 10+1 라우팅을 통해 더 높은 처리량과 더 낮은 청구를 달성하여 32K+ 긴 컨텍스트 및 일괄 처리 시나리오의 AI 워크로드에 적합합니다.
Q: Qwen3-32B 및 Qwen3-235B로 모델을 선택하는 방법은 무엇입니까?
A: 비용 효율성과 장기적인 상황 효율성을 추구하려면 Qwen3-Next-80B-A3B를 선택하십시오. 절대적인 최고 품질과 최대 컨텍스트가 필요한 플래그십 요구 사항은 235B 전에 고려됩니다. 안정적인 재고 생산 라인은 제어 기준선으로 32B에서 일시적으로 유지될 수 있습니다.
Q: 다중 토큰 예측 및 투기적 디코딩은 엔지니어링에서 어떻게 작동하나요?
A: MTP를 활성화한 후 큰 병렬 디코딩 창을 사용하고 거부율을 모니터링합니다. 추측 디코딩과 결합하면 실제 대기 시간을 더욱 줄일 수 있지만 다양한 작업이 품질에 미치는 영향을 관찰해야 합니다.
Q: Instruct 버전과 Thinking 버전의 차이점은 무엇입니까?
A: Instruct는 지침 준수 및 일반 작업을 지향합니다. 사고는 사고와 추론의 사슬을 강화하여 계획 및 도구 사용에 더 안정적으로 만들고 복잡한 검색 및 긴 연결 작업에 더 적합합니다.