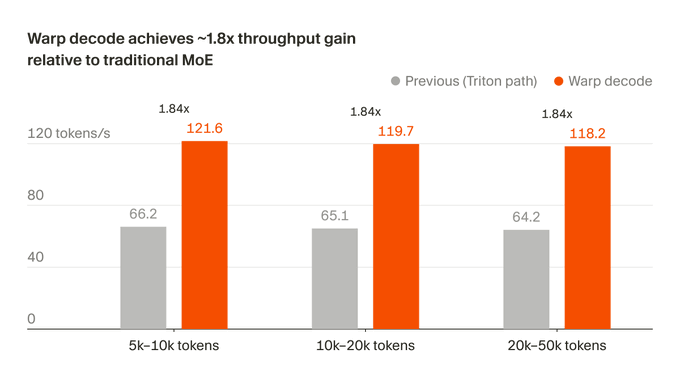
Cursor 近日披露,其在 Blackwell GPU 上重构了 MoE 模型 的 token 生成路径,并将这套方法命名为 warp decode。官方称,这项底层优化带来 1.84 倍推理吞吐提升,同时让输出结果更接近 FP32 参考值;相关改进也已用于 Composer 的训练流程,以加快模型迭代和版本发布。
Cursor把MoE解码重写了一遍
这次更新的核心,不是单纯给模型换一块更快的 GPU,而是改写 MoE 在 Blackwell 上的 decode 方式。传统方案按 experts 组织计算,Cursor 则把并行轴翻转到 outputs,让每个 warp 负责一个输出值,而不是围着专家路由打转。
这种调整瞄准的是小批量 decode 场景。MoE 模型在生成单个 token 时,原本有不少步骤都耗在数据整理、搬运和中间缓冲上,真正用于计算的比例并不高。warp decode 的意义,就是把这些额外环节尽量压掉。
1.84倍提速背后是推理链路变短
按 Cursor 的说法,warp decode 把整层 MoE 计算压缩成两个 kernel:moe_gate_up_3d_batched 和 moe_down_3d_batched。中间不再依赖多次 staging、跨 warp 同步和额外 buffer,推理路径比传统 expert-centric 方案更短。
更关键的是,这次优化没有停在“更快”上。官方同时强调,输出结果相对 FP32 参考值更接近,这让 warp decode 不只是吞吐优化,也更像一次兼顾数值表现的底层重构。对代码生成模型来说,稳定性往往和速度一样重要。
Composer开始吃到系统层优化红利
Cursor 在原始表述里把这次更新直接连到了 Composer。官方给出的逻辑很明确:预训练数据和 RL 决定模型上限,但推理链路的效率,会影响研究、训练和验证反馈跑得有多快,而这正关系到 Composer 版本更新节奏。
这也解释了为什么 Cursor 会单独强调这项工程工作。对 AI 公司来说,底层 kernel 优化不只是基础设施改良,它会反过来影响模型开发速度、发布频率,以及最终交付给开发者的体验。
围绕 Blackwell GPU 重写 MoE decode,说明大模型竞争正在回到底层执行效率。Cursor 这次没有讲更大的参数规模,而是把重点放在吞吐、精度和迭代速度上。对 Composer 来说,这类系统层优化能否持续转化为更快更新,可能比一次版本命名变化更值得关注。



