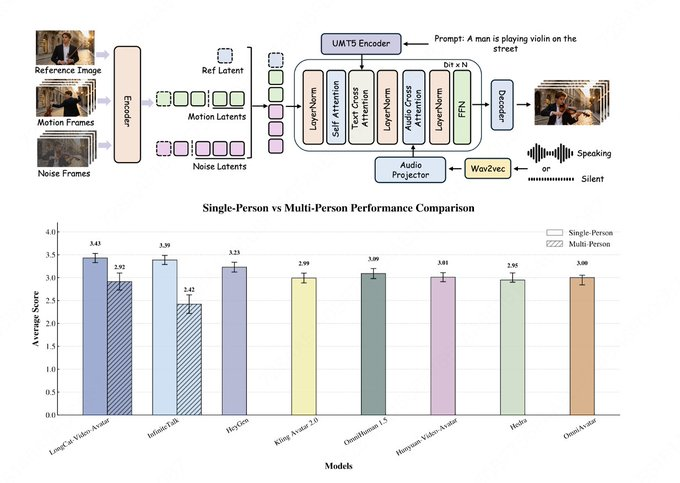
메이투안의 롱캣 팀은 롱캣-비디오 코드베이스 업데이트에서 롱캣-비디오-아바타를 출시한다고 발표했으며, 동시에 프로젝트 페이지와 허깅 페이스 웨이트를 출시했습니다. 롱캣-비디오 아키텍처를 기반으로 하며, 이 모델은 오디오-텍스트-비디오(AT2V), 오디오-텍스트-이미지-비디오(ATI2V), 그리고 오디오 조건에 따른 비디오 연속을 지원하며, 단일 인물, 다중 문자, 장시간 콘텐츠 생성을 지원합니다.
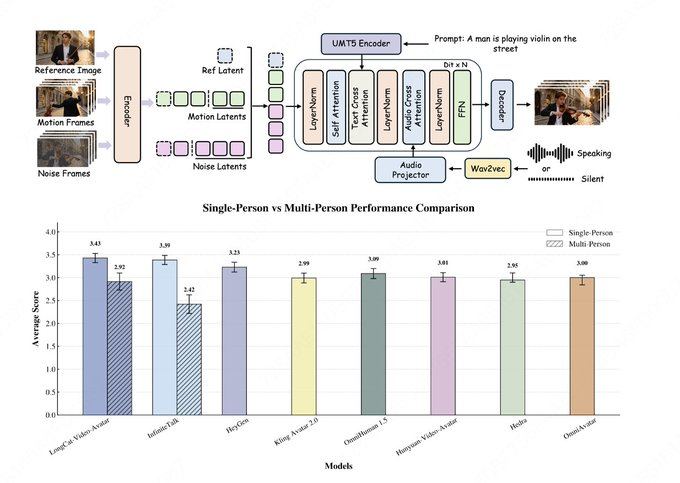
공개 자료에 따르면, LongCat-Video-Avatar는 긴 시퀀스 안정성과 보다 자연스러운 동적 성능에 중점을 둡니다: 크로스-청크 잠재 스티칭은 긴 비디오 생성에서 열화와 이음새 문제를 줄이고, 참조 건너뛰기 주의(Reference Skip Attention)를 사용해 "하드 카피" 트레이스를 줄이면서 정체성 일관성을 유지합니다; 동시에, 음성 신호에 대한 과도한 의존도를 줄이고 너무 단단한 무음 구간 문제를 개선하기 위한 분리 가이드 전략도 제안됩니다. 연구팀은 모델 카드에서 인간 평가의 기준으로 EvalTalker를 인용하며 자연성과 현실성 비교를 보여주었으나, 외부 목록 순위와 참가자 규모 같은 세부 사항은 공개 페이지에 완전히 공개되지 않았으며, 관련 결론은 평가 논문과 재현 가능한 실험에 기반해야 합니다.
자주 묻는
질문: 롱캣-비디오-아바타는 어떤 모델인가요?
A: LongCat-Video-Avatar는 캐릭터 연기를 위한 오디오 기반 비디오 생성 모델로, 장시간 타이밍 안정성, 립싱크, 정체성 일관성을 강조합니다.
Q: 메이투안의 롱캣 팀이 출시한 롱캣-비디오-아바타는 어떤 세대 모드를 지원하나요?
A: LongCat-Video-Avatar는 AT2V, ATI2V뿐만 아니라 오디오 조건에 맞는 비디오 연속 및 긴 비디오 확장을 지원합니다.
Q: LongCat-Video-Avatar와 InfiniteTalk의 차이점은 무엇인가요?
A: LongCat-Video-Avatar는 도입부에서 보다 자연스러운 다이내믹과 안정적인 긴 시퀀스 성능을 강조하며, 참조 이미지 삽입으로 인한 '복사-붙여넣기' 아티팩트를 줄이기 위해 Reference Skip Attention을 사용합니다.
Q: LongCat-Video-Avatar를 사용할 때 개발자들이 주의해야 할 위험은 무엇인가요?
A: 개발자들은 초상화 및 오디오 라이선스, 규정 준수 및 콘텐츠 보안에 주의를 기울여야 하며, 허가 없이 남용된 캐릭터 콘텐츠를 생성하지 않도록 해야 합니다.