1. Abstract
LongCat-Image는 Meituan의 LongCat 팀이 개발한 중국어와 영어 오픈소스 이중언어 이미지 생성 및 편집 모델로, 약 6B 매개변수를 가진 하이브리드 DiT 아키텍처를 사용하며, 많은 공개 벤치마크에서 20B 수준의 오픈 소스 모델과 견줄 만하거나 그 이상을 자랑합니다. 이 프로젝트는 다국어 텍스트 렌더링, 이미지 일관성, 사실적인 효과 개선에 중점을 두고 있으며, 추론 속도와 비디오 메모리 점유를 고려하여 연구 및 비즈니스 구현에 적합합니다.
2. 핵심 기능
- 중국어와 영어 이중 언어 텍스트 기능: 복잡한 중국어 한자(희귀 문자 포함)에 대한 특별 최적화와 중국어 텍스트 렌더링 지표에서의 뛰어난 성능.
- 통합 생성 및 편집: LongCat-Image, LongCat-Image-Dev, LongCat-Image-Edit 등 텍스트 이미지, 전면 편집, 텍스트 수정 등 다양한 버전을 제공합니다.
- 경량 및 효율적인 추론: 6B 하이브리드 DiT 아키텍처는 제한된 비디오 메모리에서 저정밀도 추론을 지원하며, 속도와 품질을 균형 있게 조절합니다.
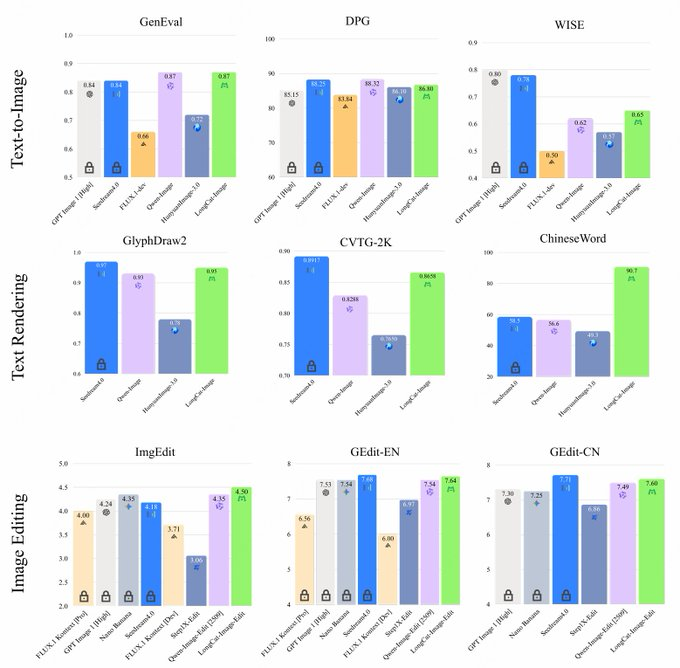
- 현실성과 정렬: 데이터 전략 및 강화학습 훈련과 결합하여 객체 구조, 스타일 및 지침의 정렬을 향상시키며, GenEval과 DPG 같은 벤치마크에서 헤드 모델과 같은 계층에 위치합니다.
- 완전한 툴체인: 오픈 소스 라이선스 하에 교육 코드, 예제, 중간 체크포인트를 제공하여 교육, LoRA, DPO 연구를 쉽게 이어갈 수 있도록 합니다.
3. 설치
- 환경 준비: CUDA를 지원하는 Python 3.10과 NVIDIA GPU를 사용하는 것이 권장되며, 16GB에서 24GB 사이의 비디오 메모리를 사용하는 것이 더 안전합니다.
- 클론 저장소:
git clone --single-branch --branch main https://github.com/meituan-longcat/LongCat-Image
cd LongCat-Image
- 설치 의존성:
conda create -n longcat-image python=3.10
conda activate longcat-image
pip install -r requirements.txt
__CODE_ INLINE_5__
- 가중치 다운로드:
huggingface-cli을 사용해 해당 저장소에서 LongCat-Image / LongCat-Image-Dev / LongCat-Image-Edit 가중치를 로컬 디렉터리로 다운로드하고 구성 내 경로를 가리킵니다.
4. 일반적인 사용 사례
- 중국어/영어 텍스트 그래픽: 포스터, 전자상거래 지도, 운영 자료 등으로, 중국어 글리프, 타이포그래피, 주제 일관성에 높은 요구가 필요합니다.
- 자연어 이미지 편집: 텍스트에 따라 전역 스타일 교체, 부분 수정, 객체 추가와 삭제, 텍스트 내용 교체 등.
- 브랜드 시각적 맞춤화: LoRA를 결합하거나 지속적으로 교육하여 브랜드 캐릭터, 색상 매칭, 구성 스타일을 확립하여 장기적으로 통합된 결과물을 제공합니다.
- 학술 및 공학 기준선: 중국어와 영어 이중언어 이미지 모델의 오픈 소스 기준선으로서, 새로운 손실, 새로운 데이터 비율 또는 새로운 강화학습 전략을 검증합니다.
5. 생태학 및 경쟁 제품
- 생태학: 공식적으로 교육 파이프라인, 추론 스크립트를 제공하며, Diffusers, ComfyUI 및 기타 생태계와 점진적으로 통합하여 기존 AIGC 프로세스에 접근하기 쉽게 합니다.
- 경쟁사 비교: Qwen-Image, HunyuanImage, Seedream, FLUX 등과 비교할 때, LongCat-Image는 중국 텍스트 렌더링 및 편집 벤치마크에서 더 작은 파라미터와 낮은 배포 임계값을 가지고 있어 명확한 우위를 가지고 있습니다. 구체적인 효과는 여전히 비즈니스 데이터와 주관적 평가와 결합되어야 합니다.
6. 제한 및 주의사항
- 연산 능력 요구사항: 고해상도 생성과 다단계 편집은 여전히 많은 비디오 메모리를 필요로 하며, 소형 비디오 메모리 장치는 해상도, 단계 수 또는 배치 크기를 줄여야 합니다.
- 언어 및 장면 범위: 주로 중국어와 영어에 최적화되어 있지만, 다른 언어나 극단적인 시각적 장면에서는 불안정하게 동작할 수 있습니다.
- 콘텐츠 준수: 모델이 부적절한 콘텐츠를 생성할 수 있으며, 실제 배포는 보안 감사, 키워드 필터링, 수동 검토와 협력해야 합니다.
- 벤치마크 외부의 불확실성: 공개된 벤치마크 결과는 비즈니스 시나리오의 성과를 완전히 반영하지 않으므로, A/B 테스트와 수동 품질 검사를 실시하는 것이 권장됩니다.
7. 프로젝트 주소
https://github.com/meituan-longcat/LongCat-Image
8. 자주 묻는 질문
: LongCat-Image가 지원하는 핵심 작업은 무엇인가요?
A: 이 기능은 이중언어 텍스트-이미지 생성, 전체 또는 부분 이미지 편집, 텍스트 콘텐츠 수정, 참조 이미지 제약 편집 등을 지원하며, 버전마다 생성, 개발, 디버깅, 편집 작업에 중점을 둡니다.
Q: LongCat-Image 추론은 얼마나 많은 비디오 메모리가 필요합니까?
답변: 공식 입장에서는 명확한 하한선을 제시하지 않으며, 일반적인 경험상 단일 카드가 16–24GB 비디오 메모리로 일반 해상도 작업을 수행할 수 있습니다; 고해상도 생성이나 배치 생성을 위해서는 여러 카드를 사용하거나 해상도와 단계 수를 줄일 수 있습니다.
Q: LongCat-Image가 중국어 텍스트 생성에서 갖는 장점은 무엇인가요?
답변: 중국어 문자 정확도, 복잡한 글리프 복원, 이미지 및 텍스트 일관성 등 벤치마크 지표에서 많은 오픈 소스 모델보다 우수한 성능을 보이며, 전체 이미지 품질과 가독성도 고려할 수 있습니다.
Q: 롱캣-이미지는 계속 교육하거나 LoRA를 미세 조정하기 쉬운가요?
답변: 네. 이 프로젝트는 SFT, LoRA, DPO, 편집 교육에 사용할 수 있는 오픈 트레이닝 툴체인과 중간 체크포인트를 갖추고 있지만, 이에 상응하는 컴퓨팅 파워와 고품질 데이터셋 준비가 필요합니다.