1. Abstract
LongCat-Imageは、MeituanのLongCatチームによる中国語と英語のオープンソースのバイリンガル画像生成・編集モデルで、パラメータは約6B、ハイブリッドDiTアーキテクチャを採用しています。これは多くの公開ベンチマークで20Bレベルのオープンソースモデルと同等かそれ以上です。 このプロジェクトは、多言語テキストレンダリング、画像の一貫性、リアルな効果の向上に焦点を当て、推論速度やビデオメモリの占有を考慮し、研究やビジネス実装に適しています。
2. コア機能
- 中国語と英語のバイリンガルテキスト機能:複雑な中国語漢字(希少文字を含む)に対する特別な最適化と、中国語のテキストレンダリング指標における卓越した性能。
- 統一生成と編集:LongCat-Image、LongCat-Image-Dev、LongCat-Image-Editなどのバージョンを提供し、テキスト画像、全体・部分編集、テキスト修正などのタスクをカバーします。
- 軽量かつ効率的な推論:6BハイブリッドDiTアーキテクチャは低精度推論をサポートし、限られたビデオメモリ上で速度と品質のバランスを取っています。
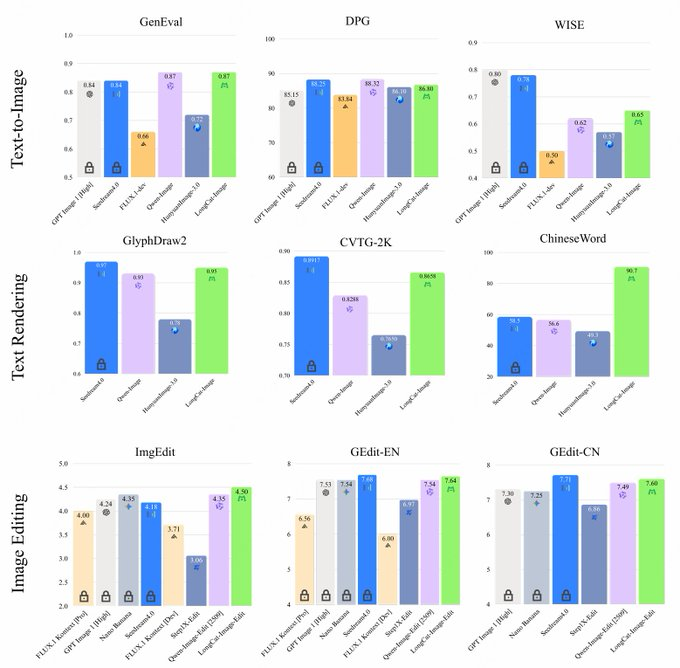
- リアリズムと整合性:データ戦略や強化学習(RL)トレーニングと組み合わせることで、オブジェクト構造、スタイル、指示の整合性を高め、GenEvalやDPGなどのベンチマークではヘッドモデルと同じ階層に位置しています。
- 完全なツールチェーン:オープンソースライセンスの下でトレーニングコード、例、中間チェックポイントを提供し、トレーニング、LoRA、DPO研究の継続を容易にします。
3. インストール
- 環境準備:CUDAをサポートするPython 3.10およびNVIDIA GPUの使用が推奨され、ビデオメモリは16GBから24GBの方が安全です。
- クローンリポジトリ:
git clone --single-branch --branch main https://github.com/meituan-longcat/LongCat-Image
cd LongCat-Image
- インストール依存関係:
conda create -n longcat-image python=3.10
conda activate longcat-image
pip install -r requirements.txt
__CODE_ INLINE_5__
- 重み付けをダウンロード:
huggingface-cliを使って対応リポジトリからLongCat-Image / LongCat-Image-Dev / LongCat-Image-Editの重みをローカルディレクトリにダウンロードし、設定内のパスを指定します。
4. 典型的なユースケース
- 中国語/英語のテキストグラフィック:ポスター、eコマース地図、運用資料などで、中国語の文字、タイポグラフィ、テーマの一貫性に高い要件が求められます。
- 自然言語の画像編集:グローバルスタイルの置換、部分的な修正、オブジェクトの追加・削除、テキスト内容の置換など。
- ブランドのビジュアルカスタマイズ:LoRAを組み合わせるか、トレーニングを継続してブランドキャラクター、色のマッチング、構図スタイルを確立し、長期的な統一成果を目指します。
- 学術・工学ベースライン:中国語と英語のバイリンガル画像モデルのオープンソースベースラインとして、新たな損失、新しいデータ比率、または新しい強化学習戦略を検証します。
5. 生態系と競合製品
- 生態系:公式にトレーニングパイプラインや推論スクリプトを提供し、Diffuser、ComfyUIなどのエコシステムと段階的に統合して既存のAIGCプロセスへのアクセスを促進します。
- 競合他社の比較:Qwen-Image、HunyuanImage、Seedream、FLUXなどのモデルと比べて、LongCat-Imageは中国語のテキストレンダリングおよび編集ベンチマークにおいて、パラメータが小さく、導入閾値も低いという明確な優位性を持っています。 具体的な効果はビジネスデータや主観的な評価と組み合わせる必要があります。
6. 制限と注意事項
- 計算能力要件:高解像度生成や多段階編集は依然として高容量のビデオメモリを必要とし、小型のビデオメモリデバイスは解像度、ステップ数、バッチサイズを削減する必要があります。
- 言語とシーンの範囲:主に中国語と英語に最適化されているため、他の言語や極端な視覚シーンでは不安定な動作をすることがあります。
- コンテンツコンプライアンス:モデルは不適切なコンテンツを生成する可能性があり、実際の展開はセキュリティ監査、キーワードフィルタリング、手動レビューと協力する必要があります。
- ベンチマーク外の不確実性:公開ベンチマークの結果はビジネスシナリオのパフォーマンスを完全に反映していないため、A/Bテストと手動品質検査の実施が推奨されます。
7. プロジェクトアドレス
https://github.com/meituan-longcat/LongCat-Image
8. よくある質問
Q: LongCat-Imageがサポートするコアタスクは何ですか?
A: バイリンガルのテキストから画像への生成、全体・部分画像編集、テキスト内容の修正、参照画像制約編集などをサポートしており、バージョンによって生成、開発、デバッグ、編集のタスクに重点が置かれています。
Q: LongCat-Image推論にはどれくらいのビデオメモリが必要ですか?
A: 公式には明確な下限は示されていませんが、一般的な経験としては、1枚のカードで16〜24GBのビデオメモリで通常の解像度処理が可能です。 高解像度やバッチ生成の場合は、複数のカードを使うか、解像度やステップ数を減らすことができます。
Q: 中国語のテキスト生成におけるLongCat-Imageの利点は何ですか?
A: 中国語の文字精度、複雑なグリフ復元、画像とテキストの整合性などのベンチマーク指標において、多くのオープンソースモデルを上回る性能を発揮しつつ、全体的な画像品質や可読性も考慮しています。
Q: LongCat-Imageは継続トレーニングやLoRAの微調整は簡単ですか?
A: はい。 このプロジェクトはオープンなトレーニングツールチェーンと中間チェックポイントを持ち、SFT、LoRA、DPO、編集トレーニングに利用できますが、対応する計算能力と高品質なデータセットの準備が必要です。