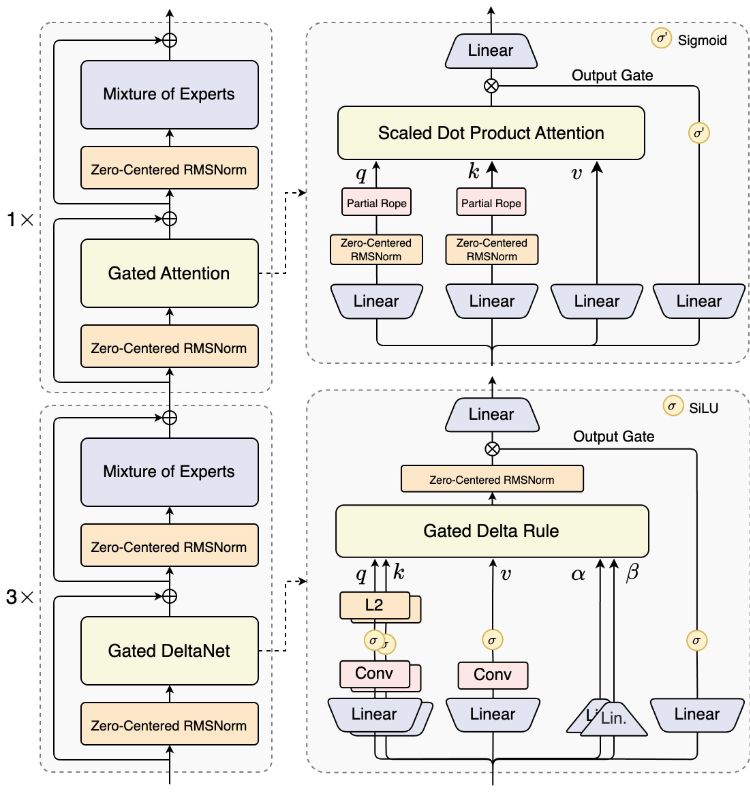
Anthropicは、ClaudeのようなAIエージェントを使用してツールを設計、評価、反復するというエンジニアリング方法論を公開しています。 中心的な焦点は、MCP ツール、体系的な評価、および説明の最適化であり、エージェントが回り道を減らし、トークンの消費を減らし、より多くのことを成し遂げることができます。
1. 結論から 1: 優れたツールの 5 つの鉄則
1. 長い
AI エージェントは開発者ではなく、冗長なツールは気を散らします。 汎用リストを検索タイプに置き換えるなど、価値の高いワークフローを中心に少数の高品質のツールを設計して、タスクの意図を検証可能な出力と直接一致させます。
2. 明確な命名と名前空間
ツール機能の重複や誤用を減らすために、サービスとリソースのプレフィックスに応じた名前空間。 モデルが異なれば、プレフィックスとサフィックスの命名に対する感度も異なるため、評価データを使用してスキームを決定する必要があります。
3. 「シグナリング」のコンテキストを返す
優先順位は、後続のアクションを駆動できる重要な情報とセマンティック識別子、および価値の低いフィールドに戻されます。 必要に応じて、読みやすさと連結機能を考慮して、詳細で合理化されたresponse_formatを提供します。
4. トークン効率を重視して設計
ページネーション、フィルタリング、切り捨てはデフォルトで有効になっており、無効な再試行やコンテキストの無駄を避けるために、実用的な改善ガイドラインがエラーメッセージに示されています。
5. プロンプト プロジェクトとして「ツールの説明」を使用する
入力と出力は明確でなければならず、例は実際のビジネスに近いものでなければなりません。 説明を少し調整するだけで、ツール呼び出しの成功率と完了率が大幅に向上します。
2. 実装方法: プロトタイプ→評価→共創のクローズドループ
1. 最初にプロトタイプを作成し、MCP に接続
するClaude コードを使用して、利用可能な最小限のツールとドキュメントをドラフトし、ローカル MCP サーバーまたはデスクトップ拡張機能をカプセル化し、エージェントでクローズドループのセルフテストをテストしてから、プログラムによる実験用の API にアクセスします。
2. 体系的な評価
実際のデータと複雑なタスクを使用して評価セットを生成し、エージェントに完全なツール呼び出しループを実行させ、時間、呼び出し数、トークン消費、エラーの種類を記録し、精度以外の多次元指標で意思決定を支援します。
3. エージェントと協力して最適化します
転写と失敗サンプルを Claude に評価して分析し、ツールの実装と説明をバッチで改善して、新しい変更が一貫性を崩すのを防ぎます。 フィットが左テストのセットのセットに限定されていないことを確認します。
3. エンジニアの操作リスト
(1)
単一の目的、明確な入力命名、検証可能な出力、および自然言語識別の優先再利用を備えたツールを設計します。
(2) パフォーマンス
ツールの応答の上限を制限し、1 つの大きなパッケージではなく、複数の正確な検索を優先します。
(3) Observable
Tool の呼び出しログ、失敗の理由、コンテキストの要約は、簡単に回帰できるように保持されます。
(4) セキュリティ
読み取り専用ツールと書き込み専用ツールを区別し、潜在的に破壊的な操作をマークし、手動アクセス制御を設定します。
よくある質問 (Q&A)
Q: AI エージェントにツールをより多く使用させるにはどうすればよいですか A
: ツールの説明から始めて、実際のシナリオの例とパラメーターの制約を示します。 評価データを使用して構造に名前を付けて出力し、読みやすさと連結の両方を考慮して、必要に応じて詳細かつ簡潔なリターンを提供します。
Q: エンタープライズレベルのエージェントにとっての MCP の実際の価値は何ですかA
: MCP は、マルチサーバーとマルチツールのアクセスを統合し、名前空間の管理と権限階層を容易にし、エージェントが混乱することなく何百ものツールを安定して呼び出せるようにします。
Q: トークンのコストが制御不能になった場合はどうすればよいですか
?A: ツール層でのページネーションとフィルタリング、応答単語数の上限の設定、エラーコピーライティングの最適化。 1 つの大きな検索を複数の小さな検索に置き換えるようにエージェントをガイドします。
Q:ツールが本当に良くなったかどうかを評価する方法
A:ビジネスに近いタスクセットとセットセットを確立し、精度、通話回数、消費時間、トークンを記録します。 変更前後の実際のタスクと複雑なタスクの完了を改善しました。