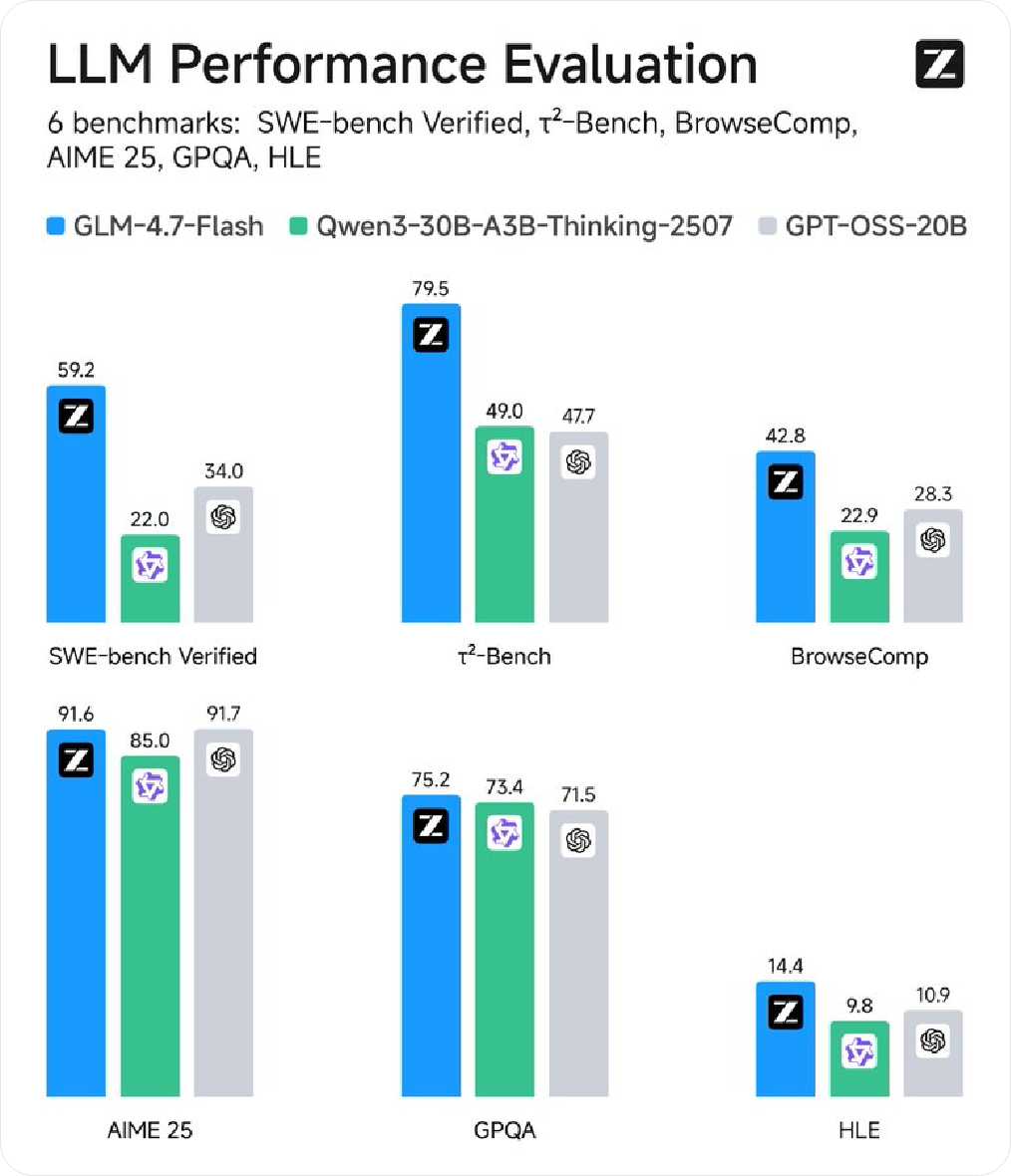
関連アカウント Z.ai Xに関する情報を掲載し、「ローカルコーディングおよびエージェントアシスタント」として位置づけられた新モデルGLM-4.7-Flashを紹介し、30Bレベルでの高いパフォーマンスと効率をバランスよく両立させ、軽量な展開オプションとして適していることを強調しました。 同期情報によると、モデルの重みはすでにHugging Faceで利用可能で、Z.ai を通じたAPI呼び出しもサポートしています。
公式開発者ドキュメントでは、GLM-4.7-Flashを「1の同時実行」制限を持つ無料ティアモデルとして説明されています。 GLM-4.7-FlashXは「より高速で経済的」なオプション版も提供されています。 プログラミングに加え、公開紹介では創作、翻訳、長期文脈作業、ロールプレイなどのシナリオでも使用することが推奨されています。
「ローカル実行」の実際の閾値は依然として展開方法やハードウェアリソースに依存します。 さらに、無料プランの同時実行および商用利用条件は、デモレベルのものを普遍的なユーザビリティの約束と誤解しないよう、プラットフォームの最新の価格および利用規約ページに基づいて設定すべきです。
よくある質問
Q: GLM-4.7-Flashの中核的な位置づけは何ですか?
A: GLM-4.7-Flashは軽量な展開に重点を置き、ローカルコーディング支援やエージェントワークフローに重点を置いています。
Q: GLM-4.7-Flashはモデル重量のダウンロード機能を提供していますか?
A: GLM-4.7-Flashの重りはすでにHugging Faceのzai-orgアカウントで入手可能です。
Q: GLM-4.7-FlashのAPIは無料ですか?
A: Z.ai のドキュメントではGLM-4.7-Flashを無料版と記載していますが、デフォルトの並行回数は1回です。
Q: GLM-4.7-FlashXとGLM-4.7-Flashの違いは何ですか?
A: 一般の説明では、GLM-4.7-FlashXはより高速かつコスト効率が高く、高頻度通話シナリオを対象としています。
Q: GLM-4.7-Flashはプログラミング以外の用途に適していますか?
A: 公開された導入では、創作、翻訳、長期的な文脈作業、ロールプレイなどに使えると書かれています。