1. 要旨
QwenLong-L1.5は、Tongyi ZhiwenチームがQwen-Docリポジトリでオープンソース化した「長いコンテキスト推論+メモリ管理」のトレーニング後レシピのセットです。 このシステムは3つの要素を中心に展開しています。すなわち、長文のための複雑な推論データ合成、長距離列のための強化学習安定訓練手法(AEPOなど)、そして物理的なコンテキストウィンドウ外でも機能するメモリ管理フレームワーク、そして対応するモデルQwenLong-L1.5-30B-A3B(Qwen3-30B-A3B-Thinkingに基づく)がリリースされました。
2. コア機能
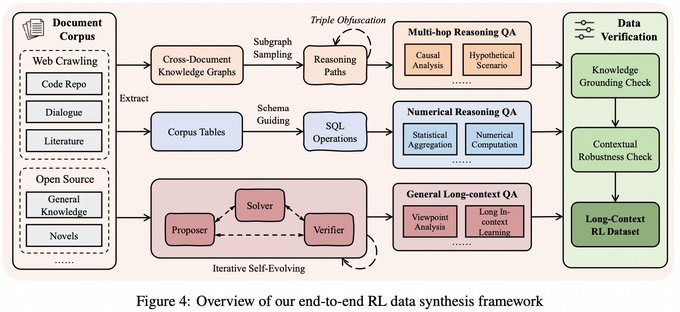
- 長文脈推論データ合成:「原子的事実分解+検証可能の組み合わせ」手法により、単純な検索作業だけでなく、複数ホップの証拠連結を必要とする長い文書推論サンプルが生成されます。
- 長序列強化学習(ROL)安定訓練:タスクバランスサンプリングなどの戦略を導入し、エントロピー関連メカニズムで訓練プロセスを調整するAEPO(適応エントロピー制御ポリシー最適化)を提案し、長文脈強化学習の一般的な不安定性問題を緩和します。
- メモリ管理と超長入力:モデルの物理ウィンドウ(例で言及されている256Kウィンドウ)で単一の推論を行い、反復的なメモリ更新と組み合わせて処理範囲を数百万またはそれ以上の入力ストリームに拡張します(論文の説明は1M〜4Mのトークンレベルのタスクをカバーしています)。
- オープンソースの再現性:モデルの重みと依存関係記述を提供し、研究者が実験を再現したり二次開発を行うのを容易にすること(モデルライセンスはApache-2.0で、特定のリポジトリ/モデルカードが適用されます)。
3. 設置
1. 環境を作る(例):conda create -n qwenlongl1_5 python==3.10 && conda activate qwenlongl1_5
2. 依存関係をインストールする:対応するディレクトリでpip3 install -r requirements.txtを実行します(実際のファイルに依存します)。
3. 強化学習トレーニングライブラリのインストール:プロジェクトの推奨に従ってverlをインストールします(例:v0.4後にpip3 install -e .に切り替えるvolcengine/verl)。
- 推論側の依存関係:トランスフォーマーを使ってモデルやトークナイザーを読み込み(推論フレームワークに応じてdevice_mapやdtypeなども調整可能です)。
4. 典型的なユースケース
- 長文Q&A(DocQA):技術文書、コンプライアンス資料、論文・報告書における段落間の複数ホップの論理と回答帰属。
- 「読んで回答する」超長資料:入力スケールが単一のコンテキストを超える場合、メモリエージェントプロセスは分割された読み込み、メモリ更新、最終的な包括的な回答に使用されます。
- エンタープライズ知識分析:構造的キーポイントの抽出、対立検出、年次報告書、入札文書、需要文書の一貫性チェック。
- 再現と訓練実践の研究:長期文脈強化学習のサンプリング戦略、報酬設計、訓練安定性および評価システムの探求に用いられます。
5. 生態系と競合製品
- 同じリポジトリエコシステム:Qwen-DocにはQwenLong-L1(以前の長文脈強化学習探索)やSPELL(自己ゲームRLフレームワーク)も含まれており、「データトレーニングエージェント」フルリンクの比較実験に適しています。
- RAG/圧縮スキームとの関係:RAGは「検索ヒット率とコンテキストスプライシング」により重点が置かれ、QwenLong-L1.5は「長文を読んだ後の推論能力と記憶処理」を重視します。 この二つは工学的に組み合わせることもあります(まず検索、その後に長い推論や記憶の要約)。
- 競合製品参照:クローズドソースのロングコンテキストモデルや様々なオープンソースのロングコンテキストのファインチューニング/スパースアワース/圧縮手法にはそれぞれのトレードオフがあります。 QwenLong-L1.5の違いは、「長い推論データ合成+長い列強化学習安定訓練+メモリエージェント」が訓練後の一連の式として与えられていることです。
6. 制限事項と注意事項
- 計算能力とレイテンシ:ロングシーケンス推論や強化学習(RL)トレーニングは、特に256Kレベルのウィンドウやメモリプロキシループではメモリやスループットが増加し、コストが大幅に増加します。
- 記憶は「絶対的に正確」ではない:記憶更新は省略や逸脱をもたらす可能性があり、重要なシナリオでは証拠のトレーサビリティと手動レビューの仕組みを保持することが推奨されます。
- 訓練再現閾値:強化学習の報酬、サンプリング、スーパーパラメータは結果に敏感です。 異なるクラスタや推論バックエンドも安定性に影響を与えることがあります。
- 外挿リスクの評価:ベンチマーク改善はすべての実際のドキュメントタスクが改善されることを意味するわけではなく、実装前にドメインデータの回帰とセキュリティ評価を行うべきです。
7. プロジェクトアドレス
https://github.com/Tongyi-Zhiwen/Qwen-Doc/tree/main/QwenLong-L1.5
8. よくある質問
Q: QwenLong-L1.5はどのような問題を解決しますか?
A: 主に「章横断、多証拠、多ホップ推論」といった長尺文書作業において、モデルが断片を取得するだけでなく、長距離にわたる完全な連鎖推論と整合性判断を可能にすることが目標です。
Q: QwenLong-L1.5のAEPOとは何で、一般的なPPOとどのように関連していますか?
A: AEPOは、エントロピー関連のメカニズムを通じて探索と強度の更新を調整する長期コンテキストトレーニングの安定性を目的とした戦略最適化手法の一つです。 これはPPOと同じ戦略最適化パラダイムに属しますが、実装の詳細や安定化方法は異なる(論文とコードの実装次第です)。
Q: QwenLong-L1.5-30B-A3Bはコンテキストウィンドウをどのくらい使用する必要がありますか?
A: このモデルは「物理的ウィンドウ+メモリ機構」の組み合わせで動作します。 例資料では、256Kウィンドウで単一の推論を行い、メモリプロキシでより長い入力に拡張可能とされています。 実際に利用可能な長さは推論フレームワーク、メモリ、構成によって異なります。
Q: トレーニングではなく推論だけがしたいのですが、QwenLong-L1.5を一番早く始めるにはどうすればいいですか?
A: Transformersを直接使い、モデル倉庫から重みやトークナイザーを読み込み、長文や質問プロンプトを準備します。 メモリプロキシのプロセスを再現するには、プロジェクトのサポートスクリプトおよび論文説明を参照してください。
Q: QwenLong-L1.5とRAGのどちらを選ぶべきですか?
A: 必ずしもそうとは限りません。 RAGは「見つける」問題を解決し、QwenLong-L1.5は「読むことと理解すること、遠くまで押し進めること、そして記憶すること」を強調しています。 工学の実践でよくある組み合わせは、「検索絞り込み+長い推論/記憶の要約」を組み合わせて複雑な質問と回答を完成させる方法です。