Xiaomi MiMo et l’équipe Core de grands modèles Xiaomi ont publié et ouvert des ressources liées à MiMo-V2-Flash, le positionnant comme un modèle de langage de base pour le raisonnement rapide et les flux de travail d’agents, et les données de déploiement du poids et d’inférence du modèle sont fournies simultanément aux développeurs et aux chercheurs.
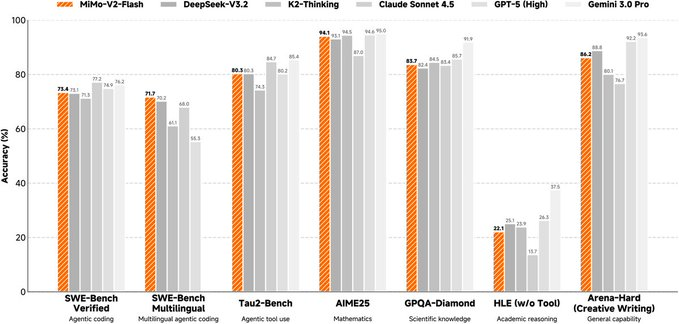
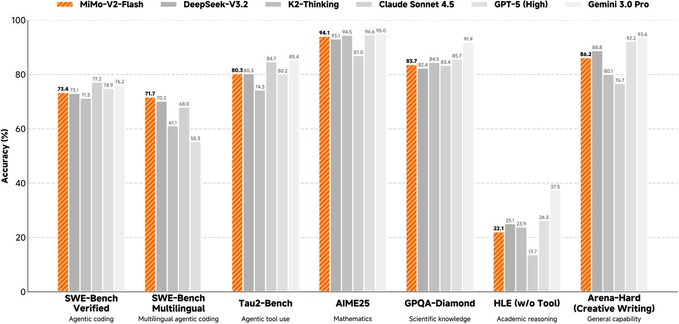
Le modèle est une architecture Mélange d’Experts (MoE) avec un paramètre total d’environ 309B, une activation d’environ 15B lors de l’inférence, et supporte une longueur de contexte maximale d’environ 256K. Sa conception à attention mixte entrelace l’attention de fenêtre coulissante avec l’attention globale proportionnellement, et utilise une fenêtre plus petite pour compresser la surcharge du cache KV. Parallèlement, un module de prédiction multi-jetons (MTP) léger est introduit pour améliorer la vitesse de décodage de sortie, et l’officiel fournit également des poids MTP multi-couches supplémentaires pour la recherche communautaire. La page modèle et le dépôt fournissent des points d’entraînement et de post-entraînement (y compris les itinéraires FP8 mixte de précision et d’apprentissage par renforcement/distillation orienté agents), et listent plusieurs résultats d’évaluation pour comparaison.
Il convient de noter que ces modèles MoE ultra-à grande échelle exigent beaucoup de puissance de calcul et de cadres d’inférence, et que les résultats d’évaluation ainsi que les effets réels sur l’entreprise peuvent être influencés par les invitations, les chaînes d’outils, ainsi que par des stratégies parallèles de quantification et d’inférence. Avant une utilisation commerciale et une redistribution, vous devriez également vérifier les termes spécifiques de licence et la portée de la page du modèle et du dépôt de code.
FAQ
Q : Quel type de modèle est le MiMo-V2-Flash ?
R : MiMo-V2-Flash est un modèle de langage de base MoE publié par l’équipe MiMo de Xiaomi, destiné à l’inférence rapide et aux scénarios de tâches d’agent.
Q : Quelle est la taille des paramètres et la longueur contextuelle de MiMo-V2-Flash ?
R : Les informations publiques montrent que ses paramètres totaux sont d’environ 309B, son activation d’environ 15B, et qu’il supporte une longueur de contexte maximale d’environ 256K.
Q : Quels problèmes le MiMo-V2-Flash résout-il principalement avec une « attention mixte » et le MTP ?
R : L’attention mixte se concentre sur la réduction du coût de mise en cache KV liée à l’inférence de contexte long, tandis que le MTP se concentre sur l’amélioration du débit et de la rapidité de la sortie lors de l’étape de décodage.
Q : Où puis-je trouver les poids des modèles et les rapports techniques pour MiMo-V2-Flash ?
R : Les poids des modèles sont disponibles sur Hugging Face, le code et les rapports techniques sont disponibles dans le dépôt GitHub, et le blog officiel ainsi que les articles LMSYS sont également organisés.
Q : Quel est le puits le plus courant sur lequel le MiMo-V2-Flash doit marcher lors du déploiement ?
R : Les problèmes courants incluent un manque de mémoire/bande passante, un support incomplet du cadre d’inférence pour MoE et MTP, ainsi que une quantification et une configuration parallèle inadéquates entraînant des fluctuations de vitesse ou de qualité.