1. Abstract
LongCat-Image est un modèle open source bilingue de génération et d’édition d’images en chinois et en anglais développé par l’équipe LongCat de Meituan, avec des paramètres d’environ 6 B, utilisant une architecture hybride DiT, comparable ou même supérieure à certains modèles open source de niveau 20B dans de nombreux benchmarks publics. Le projet vise à améliorer le rendu de texte multilingue, la cohérence des images et les effets réalistes, et prend en compte la vitesse d’inférence et l’occupation de la mémoire vidéo, ce qui le rend adapté à la recherche et à la mise en œuvre commerciale.
2. Caractéristiques principales
- Capacité bilingue en texte chinois et anglais : optimisation spéciale pour les caractères chinois complexes (y compris des caractères rares), et performances exceptionnelles dans les indicateurs de rendu du texte chinois.
- Génération et édition unifiées : Fournir LongCat-Image, LongCat-Image-Dev, LongCat-Image-Edit et d’autres versions, couvrant des tâches telles que les images textuelles, l’édition entière/partielle, et la modification de texte.
- Inférence légère et efficace : l’architecture hybride DiT 6B prend en charge l’inférence à faible précision, équilibrant vitesse et qualité sur une mémoire vidéo limitée.
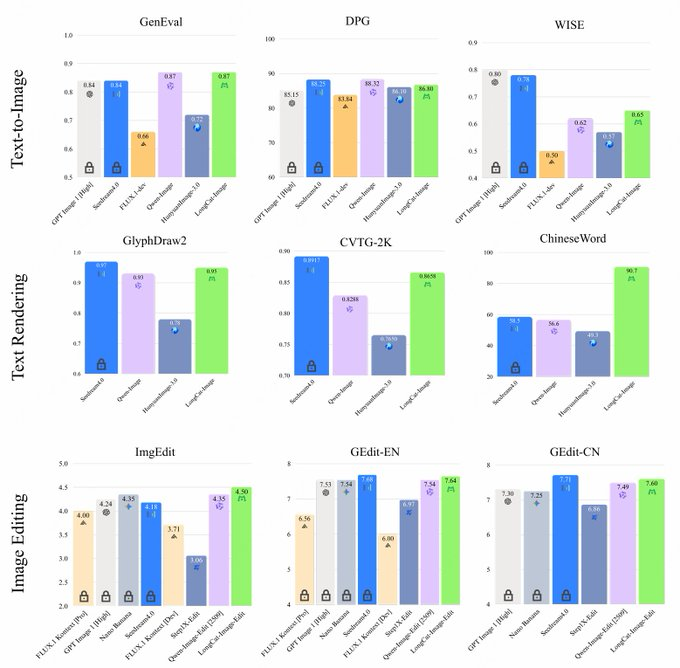
- Réalisme et alignement : Combiné à la stratégie des données et à l’entraînement RL, il améliore l’alignement de la structure, du style et des instructions des objets, et se situe au même niveau que le modèle principal sur des benchmarks tels que GenEval et DPG.
- Chaîne d’outils complète : Fournit du code de formation, des exemples et des points de contrôle intermédiaires sous licence open source, facilitant la poursuite de la formation, de la LoRA et de la recherche DPO.
3. Installation
- Préparation de l’environnement : Il est recommandé d’utiliser Python 3.10 et des GPU NVIDIA supportant CUDA, et il est plus sûr d’utiliser une mémoire vidéo de 16 à 24 Go.
- Dépôt de clones :
git clone --single-branch --branch main https://github.com/meituan-longcat/LongCat-Image
cd LongCat-Image
- Dépendances d’installation :
conda create -n longcat-image python=3.10
conda activate longcat-image
pip install -r requirements.txt
__CODE_ INLINE_5__
- Poids de téléchargement :
Utilisez huggingface-cli pour télécharger les poids LongCat-Image / LongCat-Image-Dev / LongCat-Image-Edit du dépôt correspondant vers le répertoire local et pointer vers le chemin dans la configuration.
4. Cas d’usage typiques
- Graphiques textuels chinois/anglais : affiches, cartes e-commerce, supports opérationnels, etc., qui exigent des exigences élevées pour les glyphes chinois, la typographie et la cohérence des thèmes.
- Édition d’images en langage naturel : remplacement global de style, modification partielle, ajout et suppression d’objets, remplacement de contenu textuel, etc. selon le texte.
- Personnalisation visuelle de la marque : Combinez la LoRA ou poursuivez la formation pour solidifier les personnages de marque, l’association des couleurs et les styles de composition pour un résultat unifié à long terme.
- Référence académique et technique : En tant que référence open source pour les modèles d’images bilingues en chinois et en anglais, valider les nouvelles pertes, les nouveaux rapports de données ou de nouvelles stratégies RL.
5. Écologie et produits concurrents
- Écologie : Fournir officiellement des canes de formation, des scripts d’inférence, et intégrer progressivement avec Diffusers, ComfyUI et d’autres écosystèmes pour faciliter l’accès aux processus existants de l’AIGC.
- Comparaison des concurrents : Comparé à des modèles tels que Qwen-Image, HunyuanImage, Seedream et FLUX, LongCat-Image présente des avantages évidents dans les benchmarks de rendu et d’édition de texte chinois, avec des paramètres plus petits et des seuils de déploiement plus faibles. L’effet spécifique doit encore être combiné avec des données métier et une évaluation subjective.
6. Limitations et précautions
- Exigences en puissance de calcul : la génération haute résolution et le montage en plusieurs étapes nécessitent toujours une mémoire vidéo élevée, et les petits dispositifs mémoire vidéo doivent réduire la résolution, le nombre d’étapes ou la taille du lot.
- Langue et plage de scènes : principalement optimisées pour le chinois et l’anglais, d’autres langues ou des scènes visuales extrêmes peuvent être instables.
- Conformité au contenu : Le modèle peut générer du contenu inapproprié, et le déploiement réel doit coopérer avec des audits de sécurité, le filtrage des mots-clés et la révision manuelle.
- Incertitude en dehors du benchmark : Les résultats publics des benchmarks ne représentent pas entièrement la performance des scénarios métier, il est donc recommandé de réaliser des tests A/B et des inspections de qualité manuelles.
7. Adresse du projet
https://github.com/meituan-longcat/LongCat-Image
8. FAQ
Q : Quelles tâches principales LongCat-Image supporte-t-elle ?
R : Il prend en compte la génération bilingue texte en image, la retouche d’image entière/partielle, la modification du contenu textual, la modification de contraintes d’image de référence, etc., et différentes versions mettent en avant leurs propres tâches de génération, développement, débogage et édition.
Q : Quelle quantité de mémoire vidéo nécessite l’inférence LongCat-Image ?
R : L’officiel ne donne pas de limite inférieure stricte, et l’expérience générale est qu’une seule carte peut exécuter des tâches en résolution régulière avec 16 à 24 Go de mémoire vidéo ; Pour la haute résolution ou la génération en lot, vous pouvez utiliser plusieurs cartes ou réduire la résolution et le nombre d’étapes.
Q : Quels sont les avantages de LongCat-Image dans la génération de texte chinois ?
R : Il surpasse de nombreux modèles open source dans des indicateurs de benchmark tels que la précision des caractères chinois, la restauration complexe des glyphes, ainsi que la cohérence des images et du texte, tout en tenant compte de la qualité globale de l’image et de la lisibilité.
Q : LongCat-Image est-il facile à poursuivre ou est-il un réglage fin LoRA ?
R : Oui. Le projet dispose d’une chaîne d’outils d’entraînement ouverte et d’un point de contrôle intermédiaire pouvant être utilisé pour la formation SFT, LoRA, DPO et édition, mais nécessite la préparation de la puissance de calcul correspondante et des ensembles de données de haute qualité.