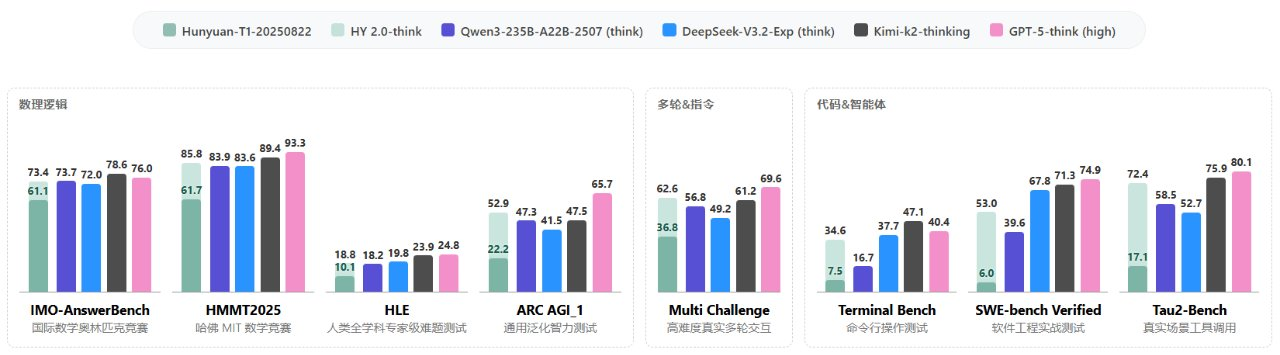
L’équipe de Tencent Hunyuan a annoncé la sortie officielle de la dernière version du modèle de langage, Tencent HY 2.0, qui est ouverte aux développeurs et aux entreprises via l’API Tencent Cloud. Cette mise à niveau adopte une architecture hybride expert (MoE) avec une échelle totale de paramètres de 406 milliards, des paramètres d’activation de 32 milliards, et supporte un maximum de 256 000 fenêtres contextuelles, ce qui est nettement amélioré en raisonnement mathématique, génération de code et exécution de tâches complexes par rapport au modèle de génération précédente. Selon l’introduction officielle, HY 2.0 a obtenu 73,4 points sur IMO-AnswerBench, et son score sur des tâches d’agent telles que SWE-bench Verified et Tau2-Bench a également fortement augmenté.
HY 2.0 propose deux types de versions optimisées : Tencent HY 2.0 Think est destiné au raisonnement profond, à la génération de code et aux scénarios d’instructions complexes, et l’interface cloud prend actuellement en charge une entrée maximale de 128K et une sortie de 64K, en se concentrant davantage sur les textes longs, les dialogues à plusieurs tours et les capacités de raisonnement difficiles ; Tencent HY 2.0 Instruct vise les conversations quotidiennes, la création et les services à forte concurrence concurrente, avec une entrée maximale de 128K et une sortie de 16K, mettant l’accent sur la réactivité et la stabilité universelle. En ce qui concerne la stratégie d’entraînement, l’officiel met l’accent sur l’introduction de l’apprentissage par renforcement à double étape RLVR + RLHF, et équilibre la « profondeur de réflexion » et l’efficacité de génération grâce à la pénalité de longueur et la conception de la zone à sable de tâches.
Actuellement, HY 2.0 est connecté à ses propres applications telles que Tencent Yuanbao, et offre des appels API et des capacités d’accès aux entreprises sur Tencent Cloud. Le prix spécifique, la stratégie de limitation actuelle et les détails techniques supplémentaires sont encore soumis à la documentation officielle de Tencent Cloud, et les données originales de certains benchmarks internes n’ont pas encore été entièrement divulguées, la comparaison de performance externe étant principalement basée sur les indicateurs et instructions publiés par Tencent.
FAQ
Q : Qu’est-ce que Tencent HY 2.0 ?
R : Il s’agit de la dernière génération du grand modèle de langage polyvalent de Tencent Hunyuan, utilisant l’architecture MoE, avec des paramètres totaux de 406B et une activation de 32B, axée sur le raisonnement, le code et les capacités de texte long.
Q : Quelles sont les versions spécifiques de cette sortie ?
R : Il existe deux principaux types de modèles textuels : Tencent HY 2.0 Think (pour le raisonnement profond) et Tencent HY 2.0 Instruct (pour le dialogue général et la rédaction).
Q : Quelles sont les spécifications contextuelles et entrée/sortie de HY 2.0 ?
R : Le modèle familial affirme supporter jusqu’à 256K contexte, et l’entrée maximale actuelle de l’interface cloud Think/Instruct est de 128K, dont la sortie maximale de Think est de 64K et la sortie maximale d’Instruct de 16K.
Q : Quelle est la principale différence entre Think et Instruction ?
R : Think est plus adapté aux tâches de « pensée lente » telles que le raisonnement complexe, la génération de code et les appels d’outils d’agent. Instruct est mieux adapté aux scénarios de chat, d’écriture et de questions-réponses professionnels, avec une forte concurrence et des besoins de réponse élevés.
Q : Est-ce entièrement open source, comment y accéder et l’utiliser ?
R : HY 2.0 propose actuellement des services commerciaux sous forme d’API Tencent Cloud, et a été intégré à certains produits Tencent.



