I. Résumé
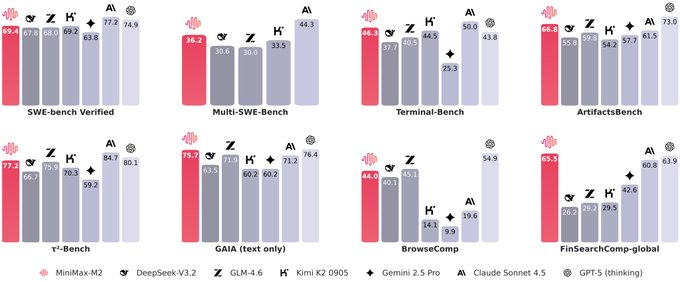
MiniMax M2 est le modèle open source de raisonnement et de programmation de MiniMax, positionné comme « Agent & Code Native ». L'introduction officielle indique : « Basé sur l'architecture Mixture-of-Experts (MoE), le modèle possède une taille totale de paramètres d'environ 230 B, mais n'en active qu'environ 10 B à la fois, ce qui permet de maintenir une qualité d'inférence élevée tout en réduisant le coût et la latence d'inférence. » MiniMax affirme que ses performances sont proches, voire comparables, à celles des assistants commerciaux classiques pour la génération de code, la planification d'outils à longue chaîne (shell, navigateur, recherche, exécution de code, etc.) et les tâches de modification multi-fichiers. Son prix est également d'environ 8 % inférieur à celui de Claude Sonnet, avec une vitesse d'inférence environ deux fois supérieure, et il est disponible gratuitement dans l'ensemble du monde pour une durée limitée dans l'agent/l'API MiniMax. Les pondérations peuvent être obtenues directement et hébergées localement sur Hugging Face, ou accessibles via l'API officielle via une interface d'inférence similaire à Anthropic/OpenAI.
2. Fonctionnalités principales
- Flux de travail du développeur : accent mis sur le « de bout en bout », prend en charge la lecture des référentiels existants, la modification de plusieurs fichiers et les boucles fermées d'exécution, de test et de correction, ciblant les scénarios d'assistant de codage basés sur IDE/CI/agent.
- Agent natif : directives intégrées d'utilisation des outils et de format d'appel, prise en charge du déclenchement à la demande d'outils externes (tels que mcp, shell, navigateur, recherche, exécution de code, etc.) et peut maintenir la cohérence cible dans les longues chaînes de tâches.
- Efficacité d'inférence : MoE est conçu pour activer seulement environ 10 octets de paramètres pour le calcul, dans le but d'obtenir une utilisation de mémoire plus faible et un débit plus élevé sur les clusters privés grand public et d'entreprise. vLLM et SGLang sont officiellement recommandés pour le déploiement local, et des hyperparamètres d'inférence (tels que température = 1,0, top_p = 0,95 et top_k = 20) sont fournis.
- Contexte long et contrôle multi-tours : Visant la « chaîne d'outils à long terme » plutôt que la réponse à des questions en un seul tour, il met l'accent sur le comportement à l'état stable dans les tâches complexes en plusieurs étapes (comme le débogage continu du même projet).
- Ouvert et commercial : pondérations publiques, instructions open source de style MIT (sous réserve du référentiel réel) ; et fournir un portail d'inférence en ligne gratuit pour une évaluation rapide.
3. Installation
- Obtenir le modèle : Téléchargez les poids et le fichier config.json des safetensors MiniMax-M2 depuis le dépôt Hugging Face. Le modèle est stocké dans des fragments utilisant la structure MoE ; vous devez donc extraire l'intégralité de tous les fragments.
- Moteur d'inférence : utilisez vLLM ou SGLang pour démarrer les services d'inférence locaux conformément au guide officiel ; les deux prennent en charge les scénarios de concurrence élevée et de contexte long et conviennent à l'hébergement sur des GPU d'entreprise/locaux.
- Paramètres d'inférence : la recommandation officielle est température = 1,0, top_p = 0,95 et top_k = 20. Un fichier chat_template.jinja compatible avec les modèles de chat courants est également fourni pour une intégration directe dans la boucle de chat/agent standard.
- Méthode API : Si vous ne souhaitez pas vous auto-héberger, vous pouvez appeler directement l'API de génération de texte / style Anthropics de la plateforme MiniMax, qui est actuellement officiellement promue comme « gratuite à l'échelle mondiale pour une durée limitée » ; cela convient pour évaluer rapidement la latence et la stabilité.
- Appel d'outils : Consultez le guide officiel d'appel d'outils. Le modèle génère les outils requis et leurs paramètres d'entrée sous forme de paramètres structurés, exécutables par un orchestrateur externe, puis les résultats sont renvoyés.
Cas d'utilisation typiques
- Assistant de codage intelligent : localise les bogues dans les bases de code existantes, propose des correctifs, modifie plusieurs fichiers et génère/met à jour des cas de test.
- Agent d'opérations et de maintenance automatisé : effectue un dépannage en plusieurs étapes et une collecte d'informations via une chaîne d'outils telle qu'un shell/navigateur/recherche, puis résume les résultats.
- Assistance R&D à long terme : Par exemple, « construire un service minimum viable → générer un Dockerfile → écrire un script de déploiement → vérifier les journaux de démarrage → corriger les erreurs », le modèle fournissant un suivi continu plutôt qu'une réponse unique.
- Assistant de déploiement privé d'entreprise : s'exécute dans l'entrepôt privé et l'environnement de dépendance privé de l'entreprise pour répondre aux exigences de conformité et de confidentialité tout en maintenant des performances d'inférence et de planification des outils proches de la qualité commerciale.
- Intégration IDE : il peut être intégré dans des environnements de développement autonomes basés sur des agents tels que Cursor, Cline, Kilo Code et Droid pour une approche cyclique « écriture-exécution-modification ».
5. Écosystème et produits compétitifs
- Écologie :
- MiniMax fournit un agent officiel (MiniMax Agent) et une API unifiée, permettant à M2 d'être utilisé directement comme assistant de développement/dépannage automatisé ;
- Au niveau de la communauté, des discussions ont eu lieu sur les exigences de compatibilité pour les GPU Transformers / GGUF / Apple série M (BF16/MPS), indiquant qu'un écosystème localisé prend forme.
- Produits concurrents :
- Systèmes commerciaux à code source fermé : Claude Sonnet, séries GPT-4o/4.1, etc., sont connus pour leur forte utilisation de code/outils, mais sont généralement coûteux et à code source fermé ;
- Les plateformes open source telles que DeepSeek, Qwen et Llama évoluent rapidement en termes de code et de fonctionnalités des agents. Les arguments de vente du MiniMax M2 sont « 230 milliards de paramètres au total, 10 milliards d'activations et un comportement de modèle quasi commercial », et soulignent ses avantages en termes de prix d'inférence et de latence. Il est important de noter que les données de comparaison spécifiques sont principalement officielles/promotionnelles et basées sur des benchmarks préliminaires ; les résultats réels doivent être vérifiés dans vos propres cas d'utilisation.
VI. Limitations et précautions
- Les performances réelles dépendent de l'exécuteur : les « performances agentiques élevées » reposent sur l'exécution correcte et le retour d'informations sur les résultats d'outils externes. Si la couche d'exécution est peu fiable, l'efficacité globale sera réduite.
- Affirmations du fournisseur vs réalité métier : Par exemple, « seulement environ 8 % du coût de Claude Sonnet et environ deux fois plus rapide » n'est que le positionnement officiel. Le coût et la latence dépendent toujours du matériel, de la taille des lots, de la longueur du contexte et de la stratégie de concurrence.
- Cohérence des tâches à long terme : dans le cas de tâches extrêmement longues et multi-branches, il est toujours nécessaire de déterminer si le modèle reste toujours sûr, conforme et exempt d'instructions destructrices, ce qui nécessite des autorisations et des audits supplémentaires du côté de l'entreprise.
- Seuil de déploiement local : bien que le paramètre d'activation soit d'environ 10 B, l'échelle de poids totale est de 230 B de fragments MoE, ce qui impose toujours des exigences en matière de bande passante, de mémoire vidéo et de temps de chargement.
- Conformité et données : l'utilisation de la modification automatique du code/de l'exécution du shell dans les scénarios privés d'entreprise nécessite des autorisations minimales strictes et des enregistrements d'audit pour éviter toute mauvaise opération dans l'environnement de production.
7. Adresse du projet
https://github.com/MiniMax-AI/MiniMax-M2
8. Questions fréquemment posées
Q : MiniMax M2 est-il vraiment « open source et disponible dans le commerce » ?
R : Le dépôt officiel et Hugging Face proposent des pondérations complètes en téléchargement, marquées comme ouvertes et permettant un déploiement local. La licence est actuellement décrite comme proche de celle du MIT/permissive. Avant utilisation, il est conseillé de vérifier la licence à l'identique, notamment les conditions commerciales et de redistribution.
Q : Qu'est-ce que « 230 B de paramètres au total / 10 B de paramètres d'activation » ?
R : Il s’agit d’une approche typique de type « MoE » (mixte d’experts) : le modèle contient un grand nombre d’experts, mais seul un petit nombre d’entre eux est programmé pour chaque inférence. Cela réduit le coût de calcul à environ 10 milliards de dollars, tout en maintenant des capacités élevées, en améliorant le débit et en réduisant le coût unitaire de l’inférence.
Q : Prend-il en charge les appels d'outils/MCP/navigateur/Shell ?
R : L'outil officiel fournit un guide d'appel d'outils. Le modèle peut fournir automatiquement les outils et les paramètres à appeler et s'intégrer à des exécuteurs externes tels que MCP, Shell, Retrievers, navigateur, etc., ce qui est adapté aux agents automatisés.
Q : Puis-je en faire l’expérience en ligne sans auto-hébergement ?
R : Oui. La plateforme MiniMax propose l'API MiniMax M2, disponible gratuitement dans le monde entier pour une durée limitée. Elle est adaptée aux premières évaluations et ne nécessite pas de cluster GPU.
Q : En quoi est-ce différent de Claude Sonnet ?
R : MiniMax affirme être proche, voire supérieur, aux modèles propriétaires classiques en termes de code, d'utilisation d'outils multi-étapes et de vitesse d'inférence. Son coût d'inférence est d'environ 8 % inférieur à celui de Sonnet, et sa vitesse est environ deux fois supérieure. Veuillez noter qu'il s'agit de benchmarks officiels ; les coûts réels varient en fonction du volume d'appels et du matériel.