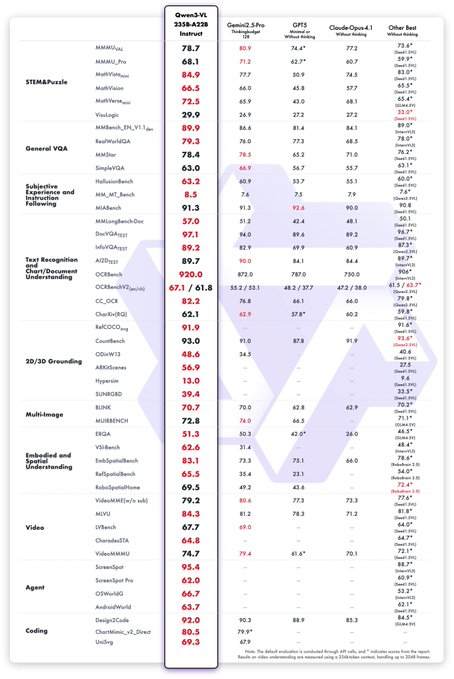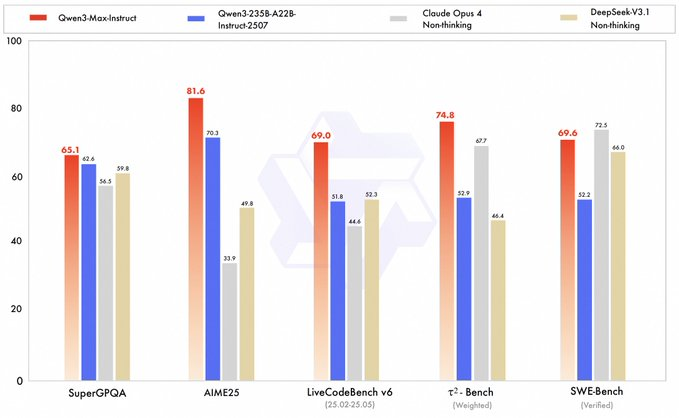
Qwen a annoncé le lancement de son modèle phare de nouvelle génération, Qwen3-Max , officiellement décrit comme « sans préversion, prêt à l'emploi ». Ce modèle est disponible en deux formats : Instruct et Thinking . Le premier est axé sur l'implémentation générale et les applications d'ingénierie, tandis que le second optimise l'utilisation des outils et le raisonnement complexe. D'après les documents de publication, Qwen3-Max-Instruct se compare avantageusement aux modèles leaders sur plusieurs benchmarks, notamment SWE-Bench, Tau2-Bench, SuperGPQA, LiveCodeBench et AIME25 . Qwen3-Max-Thinking, utilisé en mode « lourd » et combiné à l'invocation d'outils, promet des performances quasi parfaites sur les benchmarks clés.
Alibaba Cloud Model Studio a lancé CODE INLINE 0 et des versions snapshot, offrant un contexte étendu, une facturation à plusieurs niveaux et la prise en charge de la mise en cache contextuelle. Le blog officiel indique que cette série s'appuie sur l'expansion continue des données volumineuses, du pré-entraînement et de l'apprentissage par renforcement (RL), ciblant le codage, les workflows d'agents et les scénarios de documents longs. Les performances réelles, les tarifs et les quotas dépendent de la page du modèle et de la console.
Questions fréquemment posées
Q : Où puis-je l'expérimenter et l'invoquer ?
R : Qwen Chat offre une expérience en ligne ; Alibaba Cloud Model Studio ouvre l'API qwen3-max et les instantanés.
Q : Quelle est la différence entre Instruire et Penser ?
A : Instruct est destiné à une utilisation générale et à la mise en œuvre technique ; Thinking combine l'utilisation d'outils et le mode « lourd », en se concentrant sur le raisonnement profond.
Q : Quels sont les indicateurs publics ?
R : Les résultats officiels sont présentés comme étant de premier ordre/de référence sur des benchmarks tels que SWE-Bench, Tau2-Bench, SuperGPQA, LiveCodeBench et AIME25 . Veuillez consulter le blog et la page du modèle pour plus de détails.
Q : Quel est le rapport entre le contexte et la facturation ?
R : La page Model Studio affiche 256 000 contextes de niveau avec une tarification à plusieurs niveaux et prend en charge la mise en cache de contexte et les versions instantanées.
Q : Le poids est-il open source ?
R : Il s'agit d'une version de produit disponible en ligne. La disponibilité en open source sera annoncée ultérieurement.