Qwen3-Omni allie IA multimodale et raisonnement de bout en bout : un modèle unique unifie l'entrée et la sortie de texte, d'images, d'audio et de vidéo, alliant rapidité et précision. Lors de tests publics, Qwen3-Omni a obtenu des résultats exceptionnels sur un large éventail de benchmarks audio et vidéo, et propose une variété de pondérations, ce qui facilite son adoption et son développement ultérieur.
1. Pourquoi « l’IA multimodale de bout en bout » est-elle importante ?
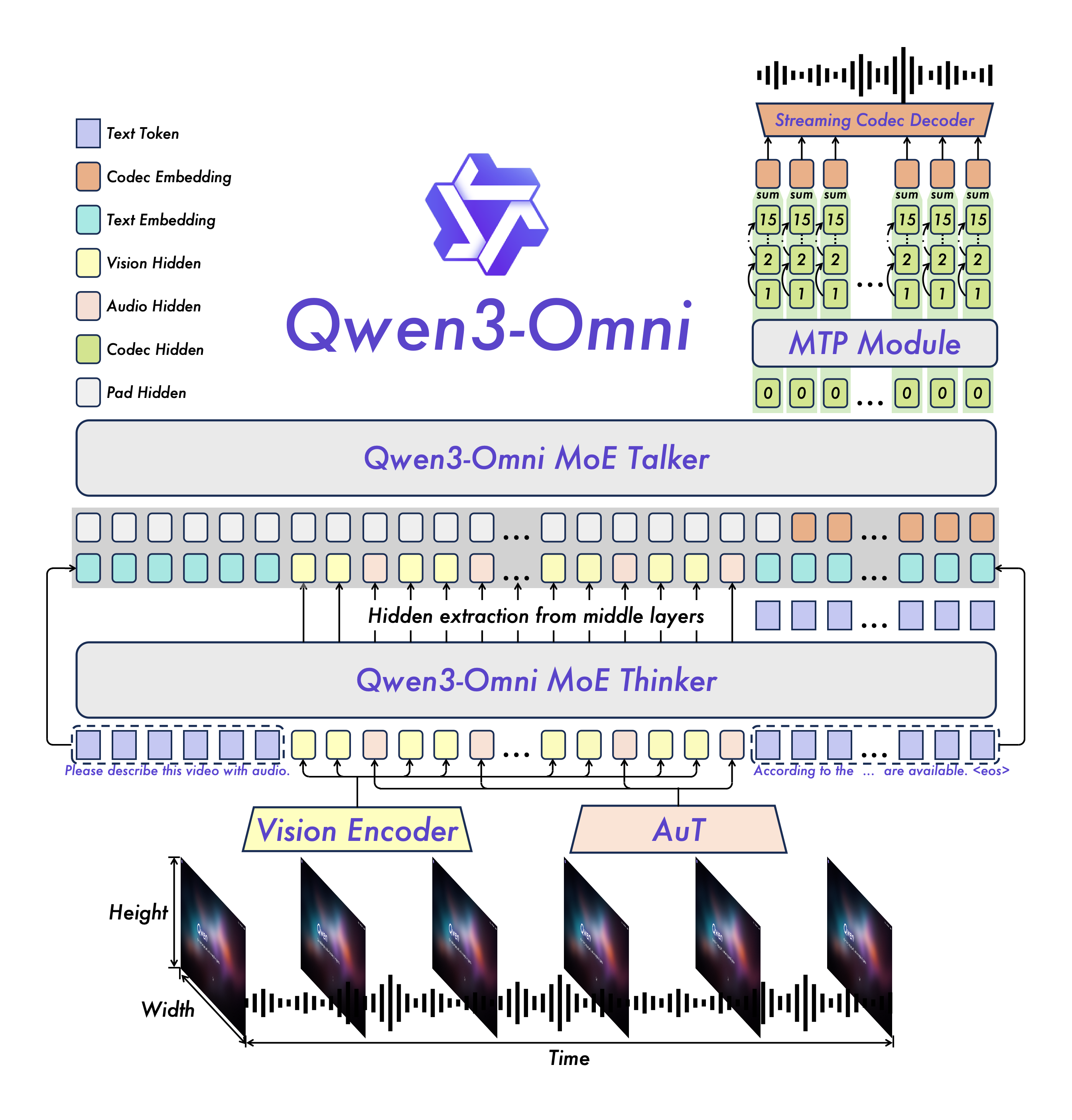
1. Des capacités d'IA multimodales véritablement unifiées
Qwen3-Omni unifie la compréhension de la parole, la compréhension de l'image, la compréhension de la vidéo et la génération de texte avec une architecture de bout en bout, réduisant la perte de performance du « prétraitement de la parole + post-traitement LLM » traditionnel et permettant un dialogue vocal à faible latence et un raisonnement multimodal de haute qualité.
2. Équilibre entre performances et latence
Qwen3-Omni a atteint des niveaux avancés dans de multiples évaluations audio et vidéo, tout en offrant une latence interactive et des capacités de compréhension audio à long terme d'environ 100 millisecondes, ce qui le rend adapté aux applications telles que les assistants vocaux, les comptes rendus de réunion, le service client en temps réel et la révision de contenu.
(1) Points saillants des indicateurs
Qwen3-Omni prend la tête dans plus de 20 benchmarks audio et audio-vidéo, avec des performances stables dans le dialogue vocal, l'ASR et la compréhension multimodale.
(2) Points saillants du projet
L'entrée vocale de bout en bout vers la sortie vocale réduit les erreurs d'épissure des modules, les invites système sont personnalisables et les appels d'outils intégrés facilitent l'expansion des processus métier.
(3) Points forts écologiques
Plusieurs modèles d'Instruct, Thinking et Captioner ont été ouverts, compatibles avec les cadres de raisonnement courants, ce qui permet aux développeurs de les mettre en œuvre facilement.
2. Comment mettre en œuvre Qwen3-Omni en entreprise
1. Liste des scénarios typiques et des solutions
Agent vocal : utilisez Qwen3-Omni pour écouter, parler, lire et écrire en temps réel, et intégrez des appels d'outils pour vous connecter au CRM et à la base de connaissances.
Réunions et entretiens : comprenez des clips audio de 30 minutes et générez des résumés, des listes d'actions et des extraits consultables.
Production de contenu : Captioner fournit des sous-titres et des descriptions à faible illusion pour améliorer l'efficacité de la liste des vidéos courtes.
Éducation et accessibilité : Interaction vocale multilingue et explications illustrées pour aider les utilisateurs malentendants et malvoyants.
2. Points de déploiement et de coût
Pour l'inférence locale, choisissez les séries 30B et A3B pour des capacités polyvalentes renforcées. Combinez quantification et mise en cache KV pour optimiser la mémoire et le débit.
Raisonnement basé sur le cloud : utilise des moteurs d'inférence et une sortie vocale en streaming pour réduire la latence de bout en bout et garantir la concurrence et la stabilité.
(1) Liste de contrôle d'intégration rapide
a. Sélectionnez un modèle : Instruct pour le suivi des instructions, Thinking pour un raisonnement complexe et Captioner pour la génération de légendes
b. Invites de gestion : utilisez les invites système pour unifier les spécifications de personnalité et d'appel d'outils
c. Outils d'accès : recherche, appel de fonction, système de bons de travail
d. Évaluation et régression : vérification à double voie à l'aide de repères multimodaux et de tests auprès d'entreprises privées
3. Suggestions de mise à niveau pour les équipes d'IA
1. Le système d'évaluation doit être multimodal et en boucle fermée
Créez un ensemble d'évaluation intégré pour le texte, les images, l'audio et la vidéo, couvrant l'ASR, le locuteur, la compréhension de la langue parlée, les réponses aux questions vidéo et la cohérence des faits.
2. Les données et la sécurité sont tout aussi importantes
Effectuer un filtrage de conformité et une détection de ligne rouge sur les entrées multimodales ; mettre en œuvre des stratégies de traçabilité et de tatouage de contenu pour les résultats de génération de parole et d'image.
3. Passer d'« assistant » à « agent »
S'appuyant sur des appels d'outils et des invites système, Qwen3-Omni se transforme en un agent d'IA multimodal avec des flux de travail exécutables, effectuant des tâches en boucle fermée depuis la compréhension du problème jusqu'à l'appel du système, puis au retour vocal.
4. Adresse du projet :
https://github.com/QwenLM/Qwen3-Omni
https://huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct
Foire aux questions (Q&R)
Q : Quelle est la différence entre Qwen3-Omni et l’IA multimodale traditionnelle ?
A : Qwen3-Omni met l'accent sur la modélisation de bout en bout et unifiée, réduisant les erreurs et les retards causés par la connexion en série de plusieurs modules, tout en conservant les capacités multimodales et textuelles.
Q : Comment choisir entre Qwen3-Omni-30B-A3B-Instruct et Thinking ?
R : Instruct est adapté au suivi des instructions et à l'appel d'outils en production, tandis que Thinking se concentre sur le raisonnement complexe et la réflexion à longue chaîne. Il est nécessaire d'équilibrer la latence et la profondeur du raisonnement en fonction de l'activité.
Q : Quel est le but de la faible illusion du Captioner ?
R : Le sous-titrage est adapté aux sous-titres vidéo, aux descriptions d'images de produits et aux scénarios d'accessibilité. Il peut réduire le risque de « discussions aléatoires basées sur des images » et améliorer l'efficacité du e-commerce et des listes de vidéos courtes.
Q : Comment connecter Qwen3-Omni au service client vocal ?
A : Utilisez les invites système pour définir le script et la stratégie de conformité, activez l'entrée et la sortie vocales en streaming et combinez les appels d'outils pour vous connecter au CRM, aux bons de travail et à la base de connaissances afin de former des questions et réponses en temps réel et des enregistrements automatiques.



