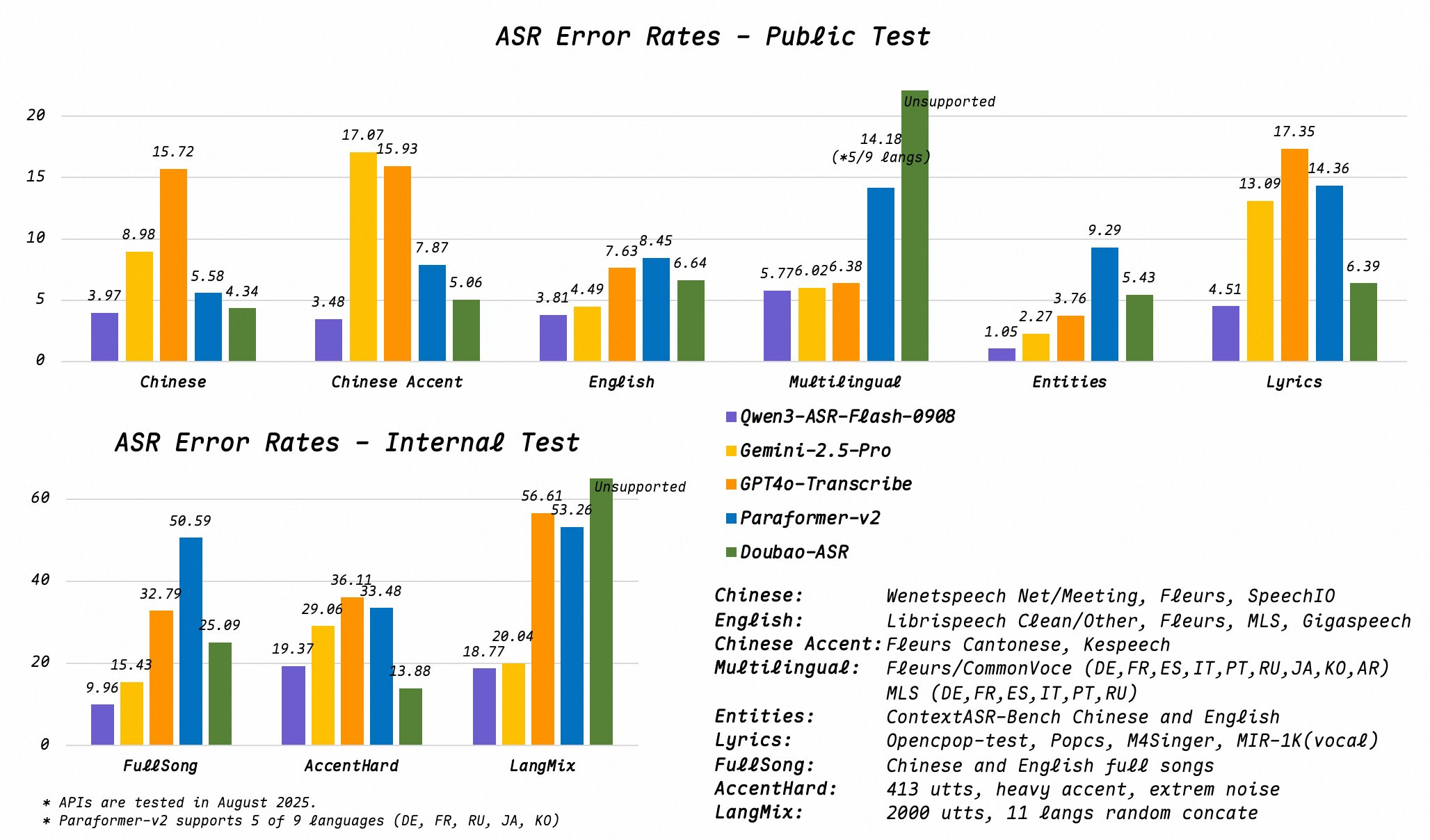
Qwen3-ASR est un modèle intégré de reconnaissance vocale par IA lancé par Alibaba Tongyi Qianwen, qui prend en charge le chinois, l’anglais et neuf langues courantes, dispose de capacités de détection automatique de la langue, et maintient toujours un taux de frappe inférieur à 8 % dans les chansons, le rap, la musique populaire, les scènes bruyantes et en champ lointain, et prend en charge le vocabulaire contextuel personnalisé, ce qui améliore considérablement l’effet de reconnaissance des noms propres, et convient à l’éducation, aux médias, au service client et à d’autres industries.
1. Principaux avantages de Qwen3-ASR
1. Détection multilingue et automatique
Qwen3-ASR prend en charge un total de 11 langues, dont le chinois, l’anglais, l’arabe, l’allemand, l’espagnol, le français, l’italien, le japonais, le coréen, le portugais et le russe, et l’IA reconnaît automatiquement les langues. Il n’est pas nécessaire de changer manuellement de modèle, ce qui améliore considérablement l’efficacité des scénarios multilingues.
2. Performances robustes dans des environnements acoustiques complexes
Qwen3-ASR peut maintenir un taux de frappe inférieur à 8 %, même dans les chansons, le rap, la musique de fond, les discours bruyants et en champ lointain. Cela le rend idéal pour la génération de sous-titres en direct, la transcription d’entretiens multilingues et les scénarios vidéo de courte durée UGC.
3. Capacité contextuelle personnalisée
Les utilisateurspeuvent coller directement des noms propres, des noms de personnes, des noms de lieux ou des termes de l’industrie en tant qu’invites contextuelles, et Qwen3-ASR donnera la priorité à ces mots pour améliorer la précision de la reconnaissance. Cette fonctionnalité est particulièrement adaptée au contenu éducatif, au service client d’entreprise, à l’identification des SKU de produits et à d’autres besoins.
2. Valeur de l’application industrielle
1. Scénarios éducatifs
Dans l’enseignement en ligne et l’enregistrement des salles de classe, Qwen3-ASR peut générer automatiquement des transcriptions et produire des notes plus précises et un résumé des points clés en combinaison avec des listes de vocabulaire spécifiques à un sujet, réduisant ainsi considérablement la relecture manuelle.
2. Scénarios multimédias
Pour les interviews multilingues et les vidéos UGC dans des environnements bruyants, Qwen3-ASR peut maintenir une précision de reconnaissance stable et la combiner avec des sous-titres de sortie standardisés en texte inversé pour réduire la charge de travail de post-édition.
3. Service client et inspection de la qualité
Les entreprises peuvent transcrire les voix du centre d’appels par lots, améliorer la précision de la reconnaissance du nom du produit et du vocabulaire du processus grâce à des contextes personnalisés, et réaliser la boucle fermée de « liaison transcription-inspection de la qualité-FAQ » en combinaison avec la base de connaissances.
3. Méthodes d’accès et points d’évaluation
1. Chemin d’accès
Lesentreprises peuvent accéder rapidement à l’environnement de production via l’API officielle, ou elles peuvent d’abord tester l’effet de reconnaissance audio dans la démo en ligne, puis migrer vers des applications à grande échelle.
2. Points clés de l’évaluation
a. Établir une référence WER pour plusieurs langues
b. Tester la stabilité dans différentes conditions telles que le bruit, le champ lointain, la BGM
c. Utiliser la terminologie de l’industrie pour vérifier l’effet des fonctions contextuelles
d. Combiner latence, coût et précision pour choisir le schéma
de déploiement approprié Foire aux questions Q :
Quelles sont les langues prises en charge par la reconnaissance vocale IA de Qwen3-ASR ?
R : Il prend en charge le chinois, l’anglais et 11 langues, dont l’arabe, l’allemand, l’espagnol, le français, l’italien, le japonais, le coréen, le portugais et le russe, et peut reconnaître automatiquement la langue.
Q : Quelle est la précision de la reconnaissance vocale par l’IA dans les chansons ou les environnements bruyants ?
R : Qwen3-ASR peut toujours maintenir un taux de frappe inférieur à 8 % dans les environnements de chanson, de rap, de musique de fond et de champ lointain, garantissant ainsi une facilité d’utilisation dans de multiples scénarios.
Q : Comment puis-je utiliser le contexte personnalisé pour améliorer la reconnaissance vocale de l’IA ?
R : Les utilisateurs peuvent coller des noms personnels, des termes, des SKU ou des mots spéciaux dans la zone de contexte, et le modèle reconnaîtra ces mots en premier, ce qui réduira considérablement le taux d’erreurs d’identification.
Q : Comment Qwen3-ASR se compare-t-il aux outils ASR comme Whisper ?
R : Whisper préfère le déploiement local open source, tandis que Qwen3-ASR fournit des API officielles et des démos en ligne, qui sont plus adaptées aux entreprises pour mettre en œuvre et réaliser rapidement des applications à grande échelle.



