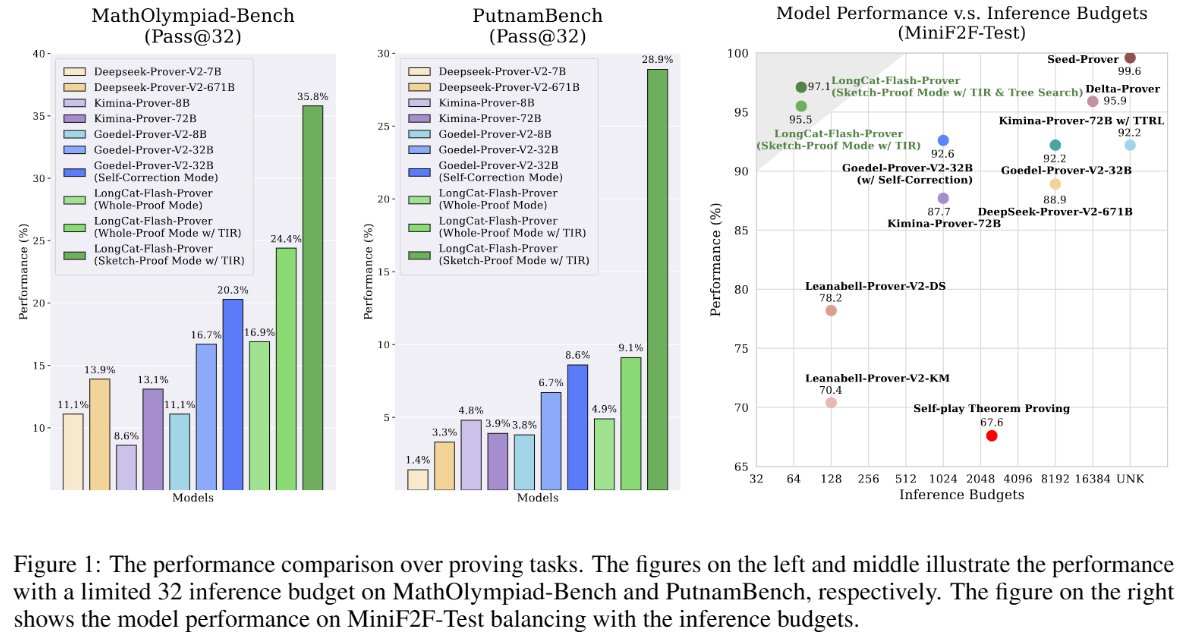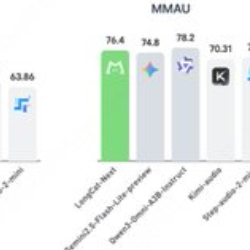
- Résumé
LongCat-Next est un modèle multimodal autorégressif natif distinct et open source, développé par l’équipe LongCat de Meituan, dans le but d’unifier texte, visuels et audio dans le même cadre. Le projet adopte l’architecture MoE, avec un paramètre total d’environ 68,5 milliards et un paramètre d’activation d’environ 3 milliards, mettant l’accent sur la réalisation collaborative de « voir, dessiner et parler » dans un seul espace de jetons discrets, offrant des capacités de compréhension, de génération et d’interaction pour des scénarios multimodaux de qualité industrielle.
- Caractéristiques principales
- Paradigme DiNA : Étendre la prédiction du jeton suivant de la langue à la multimodalité native, unifiant texte, images et audio dans un espace discret partagé.
- dNaViT : Prise en charge de l’encodage discret et de la reconstruction d’images à résolution arbitraire, en tenant compte à la fois de la compréhension visuelle et de la génération visuelle.
- Compréhension visuelle : Couvre des tâches telles que la COR, la compréhension de diagrammes, l’analyse syntaxique graphique et l’analyse de documents, et possède certaines compétences en raisonnement STEM.
- Génération visuelle : Il prend en charge la génération de résolution arbitraire avec un taux de compression élevé, ce qui est très compétitif dans les scénarios de rendu textuel.
- Capacités vocales : Soutenir la compréhension audio, l’interaction vocale à faible latence et le clonage vocal personnalisable.
- Installation
- Récupérer le code du GitHub officiel et créer un environnement d’exécution selon les instructions du dépôt.
- Les environnements recommandés incluent Python 3.10 et supérieur, Torch 2.6 et versions supérieures, Transformers 4.57.6 et supérieures, ainsi qu’Accelerate 1.10.0 et supérieures.
- Après avoir installé les exigences et dépendances supplémentaires, chargez les poids LongCat-Next depuis le Face Étreinte.
- Des exemples officiels montrent que l’inférence locale basée sur les Transformers nécessite généralement au moins 3 GPU avec 80 Go de mémoire vidéo.
- Cas d’usage typiques
- Compréhension documentaire : identification et analyse de factures, formulaires, rapports, captures d’écran et autres contenus.
- Analyse de l’interface : Comprendre l’interface logicielle, la disposition des boutons et le processus d’interaction.
- Questions-réponses multimodales : Utilisez le texte, les images et l’audio comme entrées unifiées pour un raisonnement complet.
- Génération d’images : Générez des affiches, des images avec du texte et du contenu visuel multi-résolution.
- Interaction vocale : Maîtrisez la réponse vocale aux questions, la reconnaissance vocale et la synthèse vocale personnalisée.
- Écologie et produits concurrents
- En termes d’écologie, LongCat-Next a fourni GitHub, Hugging Face, des démonstrations en ligne, des introductions de blog et des portails de rapports techniques.
- Comparé au schéma courant « encodeur visuel ou encodeur audio branché dans un LLM », LongCat-Next met l’accent sur la modélisation unifiée native.
- Comparé aux modèles de vision dédiée optimaux à point unique, aux modèles de génération d’images ou aux modèles vocaux, il bénéficie de l’avantage d’un cadre unifié et d’une couverture multitâche, mais au prix d’une complexité de déploiement plus élevée.
- Limitations et précautions
- Le seuil de déploiement est élevé, et les exigences en mémoire vidéo, bande passante et puissance de calcul globale sont évidentes.
- Les capacités de génération visuelle et de clonage vocal nécessitent une prise en compte supplémentaire des questions de sécurité, de droits d’auteur et de conformité dans les applications pratiques.
- Bien que la voie visuelle discrète soit caractérisée par l’unité de compréhension et de génération, l’effet spécifique doit néanmoins dépendre de la mesure réelle de l’activité cible.
- En tant que nouveau projet open source, ses interfaces, dépendances et bonnes pratiques peuvent continuer à évoluer.
- Adresse du projet
https://github.com/meituan-longcat/LongCat-Next
- Questions fréquemment posées
Q : Qu’est-ce que LongCat-Next ?
R : LongCat-Next est un modèle multimodal autorégressif natif et discret open source, développé par l’équipe LongCat de Meituan, qui traite le texte, les images et l’audio de manière unifiée.
Q : Qu’est-ce que DiNA, la technologie centrale de LongCat-Next ?
R : DiNA est un paradigme de modélisation qui étend la prédiction Next-Token à la multimodalité native, unifiant langage, visuels et audio avec un espace de jetons discret partagé.
Q : Que fait dNaViT de LongCat-Next ?
R : dNaViT est un module de discrétisation et de reconstruction de la vision de LongCat-Next, qui permet de comprendre et de générer des images de toute résolution.
Q : À quelles applications LongCat-Next convient-il ?
R : Il convient à des scénarios tels que l’OCR, la compréhension des graphes, l’analyse syntaxique GUI, l’analyse de documents, la réponse multimodale aux questions, la génération d’images et l’interaction vocale.
Q : Y a-t-il des exigences matérielles élevées pour les déploiements sur site LongCat-Next ?
R : Oui, des exemples officiels montrent que son déploiement a des exigences plus élevées pour la mémoire vidéo GPU, ce qui le rend plus adapté aux environnements de puissance de calcul haute performance.