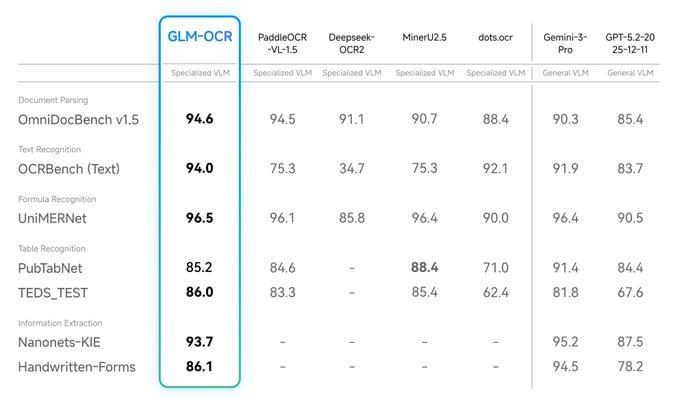
Z.ai a publié le modèle multimodal OCR GLM-OCR, qui ouvre des poids sur Hugging Face et offre une expérience en ligne ainsi que des méthodes d’appel API. Officiellement, le modèle ne dispose que d’environ 0,9 milliard de paramètres, mais il a atteint des performances de premier plan dans des tâches complexes de compréhension documentaire, couvrant des scénarios tels que la reconnaissance de formules, la reconnaissance de tables et l’extraction d’informations clés.
En termes d’utilisation des API, GLM-OCR prend en charge la saisie de PDF et d’images (JPG/PNG), avec une seule image ne dépassant pas 10 Mo, PDF ne dépassant pas 50 Mo, et un maximum de 100 pages. La sortie peut inclure des résultats Markdown et des détails de mise en page pour l’analyse analytique, la saisie de données et le prétraitement RAG. L’effet réel sera toujours influencé par la qualité du scan, le mélange de polices, l’occultation du scellement et la complexité de la mise en page, et il est recommandé de réaliser des évaluations par échantillonnage et des vérifications de conformité à la confidentialité dans l’environnement de production.
FAQ
Q : Quels problèmes GLM-OCR résout-il principalement ?
R : GLM-OCR convient à la OCR et à la compréhension de documents complexes, couvrant texte, tableaux, formules et extraction d’informations.
Q : Quelles entrées et limites de taille GLM-OCR supporte-t-il ?
R : le glm-ocr prend en charge le PDF et le JPG/PNG, les images ≤ 10 Mo, le PDF ≤ 50 Mo, jusqu’à 100 pages.
Q : Quelles sont les formes des résultats de sortie GLM-OCR ?
R : le glm-ocr peut produire des résultats textuels Markdown et renvoyer des informations structurées liées à la mise en page.
Q : GLM-OCR propose-t-il une expérience en ligne et une API ?
R : Z.ai fournit des descriptions d’interface API sur la page d’expérience en ligne et la documentation pour les développeurs.