1. Résumé
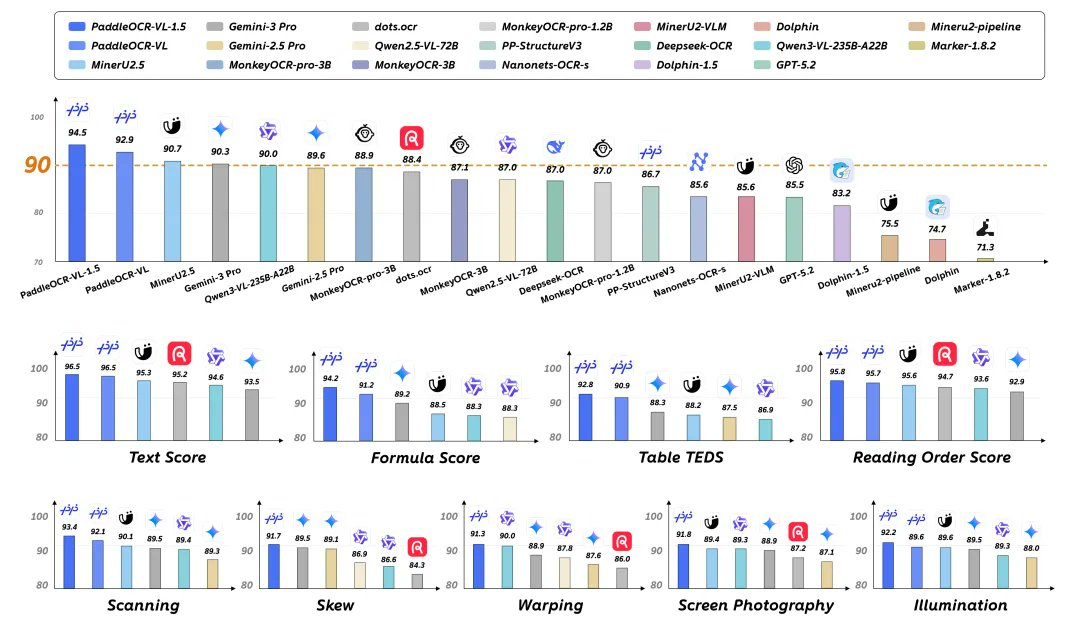
PaddleOCR-VL-1.5 est un modèle multimodal de document paramétrique 0,9B open source de PaddlePaddlePaddle, qui offre des capacités intégrées allant du positionnement de la mise en page, de l’ordre de lecture à l’analyse structurée telle que texte/table/formule, etc., pour des scénarios d’acquisition réels tels que « plier, déformer, incliner, photographie d’écran et éclairage complexe ». Les résultats officiels du public montrent qu’il atteint une grande précision sur OmniDocBench v1.5 et Real5-OmniDocBench, ce qui convient à la compréhension de documents et à l’extraction de données de haute qualité.
2. Caractéristiques principales
- Positionnement polygonal/zone irrégulière : Des polygones multipoints sont utilisés à la place de boîtes rectangulaires rigides, qui s’adaptent mieux aux limites du texte et des éléments sous distorsion courbe et perspective.
- Reconnaissance des sceaux et signatures : Ajout de la capacité de reconnaissance pour les éléments « sceau/sceau officiel », adaptée à l’extraction structurée de matériaux gouvernementaux et d’entreprises ainsi qu’aux scénarios de conformité.
- Logique d’étalement et sémantique globale : Soutenir la compréhension au « niveau du document entier » telle que la fusion de tables de dispersion et l’association hiérarchique de titres et de titres, ce qui favorise la restauration sémantique de documents longs.
- Analyse multitâche : Texte de recouvrement, tableaux, formules, graphiques et autres éléments, et fournir une sortie d’analyse de bout en bout des documents (comme Markdown/JSON).
- Léger et haut débit : les paramètres 0,9B sont pratiques pour un déploiement contrôlé par coûts ; Le matériel officiel fournit des données de débit de bout en bout sur l’A100 pour le traitement par lots de documents.
- Multilingue : Les documents officiels offrent une couverture multilingue étendue, incluant le tibétain, le bengali et d’autres langues mineures.
3. Installation
- Expérience en ligne : Utilisez directement ModelScope Online Demo pour télécharger des images ou des PDF afin de vérifier rapidement l’effet d’analyse des scènes telles que la courbure et la déformation, la photographie d’écran, etc.
- Déploiement local : cloner le dépôt PaddleOCR, installer les dépendances et les ressources du modèle selon la documentation officielle, et prioriser l’utilisation de Docker pour réduire les différences environnementales.
- Accélération d’inférence : Lorsque le débit élevé est requis, utilisez des backends d’inférence tels que FastDeploy pour un déploiement orienté service et une accélération du traitement batch, combinés à l’ajustement par file d’attente batch et aux paramètres de concurrence.
4. Cas d’usage typiques
- Structurer des scans complexes : contrats, factures, papiers, rapports, etc., convertir images/PDF en Markdown/JSON structuré utilisable.
- Restauration de table de page et de table des matières : fusionner et organiser automatiquement la table de page au niveau du titre pour améliorer la lisibilité et la récupérabilité de documents longs.
- Extraction des éléments du sceau : extraire la zone du sceau et les informations clés dans l’archivage de la vérification des matériaux et du contrôle des risques, et les lier à la revue des règles/manuels.
- Pipeline de données RAG de documents : préserver les paragraphes, tableaux, numéros de page et coordonnées d’éléments afin d’améliorer la récupération, le positionnement des citations et la traçabilité des réponses.
5. Écologie et produits concurrents
- Écologie : PaddleOCR offre une chaîne d’outils complète allant du rendu des documents, à l’analyse de mise en page, à la sortie structurée, facilitant la mise en œuvre du traitement par lots et des services en ligne.
- Produits concurrents : Les grands modèles multimodaux généraux et les solutions traditionnelles d’analyse OCR/document présentent leurs propres avantages ; PaddleOCR-VL-1.5 propose une superposition de multitâche « True Distortion Document Resolution » avec des paramètres plus petits. Les avantages et inconvénients des différents schémas dépendent de la répartition des données et des paramètres d’évaluation, et il est recommandé d’utiliser leurs propres échantillons pour les tests de régression avant la sélection.
6. Limitations et précautions
- Il existe un risque de fusion erronée entre fusion de couvertures et inférence hiérarchique : Pour les documents à disposition extrêmement irrégulière et fortement interférencée avec les en-têtes et les pieds de page, une vérification des règles et une revue d’échantillonnage sont requises.
- La reconnaissance des sceaux possède de forts attributs commerciaux : les styles de sceaux varient considérablement selon les régions/unités, et il est recommandé de compléter les stratégies de données de domaine et de seuils.
- Le débit et le coût dépendent des liens de rendu et d’inférence : le DPI du rendu PDF, la taille du lot, la concurrence et l’implémentation en back-end auront un impact significatif sur la rapidité et le coût.
- La publicité et la comparaison doivent être interprétées avec soin : si vous voyez la conclusion de la comparaison avec certains modèles généraux à code fermé, vous devez prêter attention à la cohérence de l’ensemble d’évaluation, aux mots de prompts et au traitement des entrées.
7. Adresse du projet
https://github.com/PaddlePaddle/PaddleOCR
8. Questions fréquemment posées
Q : Le PaddleOCR-VL-1.5 est-il adapté à la courbure et à la torsion de l’OCR des documents ?
R : Le positionnement officiel est destiné à la distorsion de balayage, à la distorsion de perspective et aux caméras d’écran, et offre des capacités de positionnement irrégulier en zone et de résolution de bout en bout ; Il est recommandé d’utiliser votre échantillon de collection réelle pour la vérification.
Q : Comment puis-je construire un document RAG haute précision avec PaddleOCR-VL-1.5 ?
R : Prioriser la diffusion de résultats structurés (comme Markdown/JSON), en conservant le niveau du titre, la structure du tableau, l’ordre de lecture, le numéro de page et les coordonnées. Ensuite, cliquez sur le « Bloc Paragraphe/Tableau » pour le diviser en entrepôts et créer des références traçables.
Q : Que dois-je faire si l’effet de fusion de tables d’écart est instable ?
R : En post-traitement, ajoutez des vérifications de cohérence (nombre de colonnes/similarité d’en-tête/adjacence du numéro de page), puis relisez manuellement ou revenez à « analyse par page » pour les échantillons à faible confiance.
Q : Que dois-je faire si le débit ne correspond pas aux données officielles ?
R : Vérifiez le temps de rendu PDF, la résolution d’entrée, le batch et la concurrence, l’utilisation du GPU, et si le backend d’inférence officiellement recommandé et les paramètres sont utilisés. Tout lien dans le lien de bout en bout deviendra un goulot d’étranglement.
Q : Soutenez-vous le tibétain, le bengali et d’autres langues ?
R : Les sources officielles offrent une couverture multilingue et incluent le tibétain, le bengali, etc. ; Avant le lancement, il est toujours recommandé de réaliser un échantillonnage spécial et l’acceptation de la langue cible.