1. Résumé
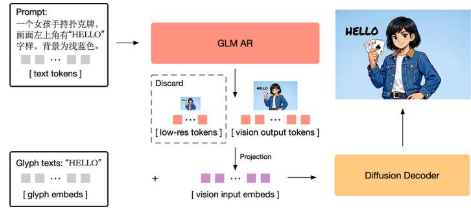
GLM-Image est un modèle de génération d’images open source issu de Z.ai, utilisant un paradigme hybride de « génération autorégressive discrète + décodage par diffusion » : le module autorégressif est responsable de la sémantique globale et de la planification de la mise en page, et le décodeur de diffusion est complété par des détails de haute fidélité. Les informations officielles indiquent que sa qualité d’image globale peut correspondre à la voie de diffusion courante, et en même temps, elle se distingue davantage dans le rendu de texte et les images à forte intensité de connaissances (affiches, PPT, diagrammes de vulgarisation scientifique).
2. Caractéristiques principales
- Architecture hybride : prendre en compte la compréhension de l’instruction (globale) et la restauration des détails (locale).
- Texte plus stable : plus adapté au texte multiligne, à la hiérarchie des titres/sous-titres et à la disposition des fiches d’information.
- Génération intensive en connaissances : Images pour « expression de l’information d’abord », telles que des affiches de diagrammes de flux et des diagrammes d’annotation.
- Diagramme de Wensheng + Tushengtu : Supporter la génération, l’édition et les tâches liées au style/cohérence (sous réserve d’exemples officiels).
3. Installation
- Obtenir le code et le poids : dépôt clone GitHub ; Téléchargez les poids des modèles sur Hugging Face.
- Inférence Python : Installer des dépendances telles que Transformers/Diffusers selon les instructions du dépôt, charger le pipeline pour la génération.
- Appel d’interface : Vous pouvez utiliser directement le point d’extrémité images/générations de l’API Z.ai pour transmettre des paramètres tels que l’invite et la taille.
4. Cas d’usage typiques
- Affiches et supports d’événement : Des graphiques promotionnels avec « texte clair et lisible + mise en page stable » sont requis.
- PPT page d’information : couvertures de chapitres, points clés, tableaux comparatifs et autres écrans riches en informations.
- Diagramme de vulgarisation scientifique et diagramme d’annotation : mettent l’accent sur la correction sémantique et la structure de l’information, plutôt que sur l’art purement stylisé.
- Sortie de cohérence de marque : Plusieurs images maintiennent le style cohérent avec le corps principal et réduisent les retravails.
5. Écologie et produits concurrents
- Écologie : Visage Écâlissant fournit des modèles et des instructions ; La documentation officielle fournit des API et des paramètres ; GitHub fournit des inférences natives et des exemples.
- Produits concurrents : Comparé aux routes grand public telles que SDXL/SD3 et FLUX, GLM-Image est plus enclin au scénario « texte + expression de connaissances » ; Les recommandations de couverture de type universel et de coût utilisent vos suggestions pour comparer et évaluer les données.
6. Limitations et précautions
- Seuil de puissance de calcul : L’architecture hybride et la génération haute résolution peuvent nécessiter un support plus élevé de mémoire vidéo/multi-carte.
- Contraintes dimensionnelles : Il est courant d’exiger que la largeur et la hauteur soient un multiple spécifique (comme un multiple de 32), sinon une erreur peut être signalée.
- Le texte doit toujours être accepté : la relecture manuelle est recommandée pour les petites tailles de polices, les polices complexes et les scénarios de mise en page multilingues mixtes.
7. Adresse du projet
https://github.com/zai-org/GLM-Image
8. Questions fréquemment posées
Q : Quels sont les avantages de l’architecture hybride « autorégression + décodage diffusion » de GLM-Image ?
R : L’auto-régression est meilleure en sémantique globale et planification de la mise en page, la diffusion est meilleure pour la complétion des détails et des textures, et elle favorise davantage la génération d’images dense en informations après combinaison.
Q : Pourquoi GLM-Image est-il plus avantageux pour rendre des images en chinois ?
R : Les documents officiels soulignent qu’il a été spécialement conçu et formé pour l’expression du texte et de l’information, rendant le texte généré plus clair et plus proche de la mise en page attendue.
Q : Pour quels scénarios très riches en connaissances GLM-Image est-il adapté ?
R : Affiches, pages d’information PPT, diagrammes de vulgarisation scientifique, images avec annotation multi-régions et informations hiérarchiques.
Q : GLM-Image peut-il faire de la génération/édition d’images ?
R : Oui, le dépôt et les pages modèles fournissent des paramètres d’utilisation pertinents et d’exemples (sous réserve de l’officiel).
Q : Que dois-je faire si GLM-Image ne peut pas fonctionner localement ?
R : Réduisez d’abord la résolution et le nombre d’étapes, utilisez une mémoire plus grande ou plusieurs cartes si nécessaire, ou utilisez plutôt l’API Z.ai.
Q : Pourquoi l’image GLM-Image génère-t-elle une erreur de taille ?
R : La raison courante est que la largeur et la hauteur ne respectent pas les multiples contraintes requises par le modèle ; Ajustez aux dimensions conformes selon le document.